¶ Description
Create a SVM model.
¶ Parameters
¶ Parameters tab
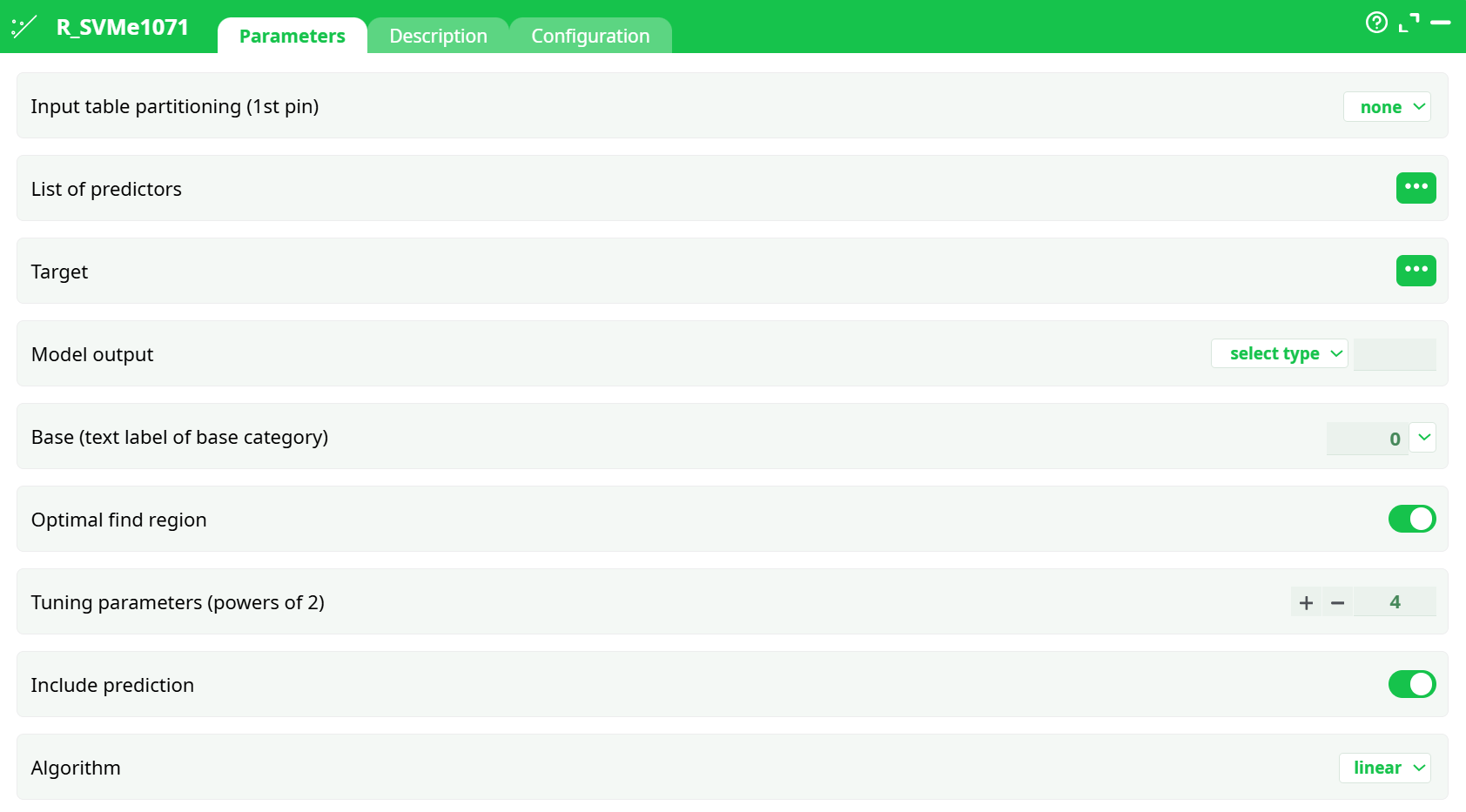
Parameters:
- List of predictors: Comma-separated list of numeric columns to use as features.
- Target: Name of the categorical response column.
- Model output: Where to persist the trained model (choose recorded data and a path, e.g.,
records/out.rModel). - Base (text label of base category): Sets the reference class label (e.g.,
Group 1). - Optimal find region: When ON, the node searches a sensible region for SVM hyper-parameters (good default).
- Tuning parameters (powers of 2): Breadth of the parameter search;
4is a safe starter, increase for more exhaustive tuning. - Include prediction: Appends the predicted class to the output table.
- Algorithm:
classificationfor categorical targets (default here).
¶ Description tab

Parameters:
- Script name
- Short description
- Revision
- Decription
¶ Configuration tab
See dedicated page for more information.
¶ About
R_SVMe1071 trains a Support Vector Machine (SVM) classifier using the e1071 R package. SVMs learn a decision boundary (a hyper-plane) that maximizes the margin between classes. With kernel functions, the model can capture non-linear relationships while still controlling complexity via regularization.
SVMs remain a solid baseline for tabular, medium-sized datasets when:
- You want a strong margin-based classifier with good generalization.
- The signal is not strictly linear (use kernels) but the number of features is moderate.
- Classes are not separable with simple linear models.
Strengths
- Robust to outliers via margin maximization and C-regularization.
- Works well on standardized numeric features; simple to tune (C, gamma).
- Can model non-linear patterns with RBF, polynomial, or sigmoid kernels.
Considerations
- Training time grows with data size; SVMs are best on small-to-medium datasets.
- Inputs must be numeric; categorical fields require one-hot/dummy encoding upstream.
- Parameter tuning (C, gamma) is important; enable the Optimal find region option or drive grid/RS tuning externally.
¶ Inputs
A single table with:
-
Predictors: one or more numeric columns.
-
Target: a categorical column (2+ levels).
- The Base parameter sets which level is treated as the reference.
Tip: Standardize or scale numeric features upstream for smoother optimization.
Configuration tips
- Clean up extra spaces: ON (prevents accidental string factors).
- Convert integers from R to meta-type:
float(keeps numeric types consistent). - If you partition the input table elsewhere in the pipeline, ensure each partition is sorted as required by upstream steps.
¶ Best Practices
- Scale features (mean-0 / unit-var) upstream for more stable margins.
- Start with small tuning breadth (
4) then increase if performance plateaus. - If you have many categorical predictors, one-hot encode them before this node; consider a tree-based model when cardinality is very high.
- For very large datasets, sample to prototype, then consider linear SVM solvers or alternative algorithms.
¶ Troubleshooting
“factor X has new levels …”
Your prediction rows contain factor levels unseen in training or a numeric column was parsed as text. Fix by:
- Enabling Clean up extra spaces; ensure readCSV parses numerics correctly.
- Verifying all predictors are numeric (no stray symbols or locale decimals).
“NN/MNL can only process numbers…”
This message belongs to a different node (NNET/MNL). For SVM, ensure you’re using R_SVMe1071 and predictors are numeric.
“cannot open compressed file 'records/out.rModel'”
Use Model output = recorded data and a simple path (e.g., records/out.rModel). Ensure the pipeline has permission to write.
Slow training / memory
Reduce tuning breadth, downsample to explore, or prefer linear kernel when relationships are close to linear.
¶ FAQ
Q: Can I use SVM for regression here?
A: This node is configured for classification. For regression, use a dedicated regression node.
Q: How do I reuse the trained model?
A: Point a scoring pipeline to the recorded model artifact (out.rModel) and the same feature schema to generate predictions.
Q: What kernel is used? Can I change it?
A: By default it’s RBF (radial). Kernel and hyper-parameters are handled inside the node; expand the tuning range if you need more exploration.
