¶ Description
Phantom buster.
¶ Parameters
¶ Parameters tab
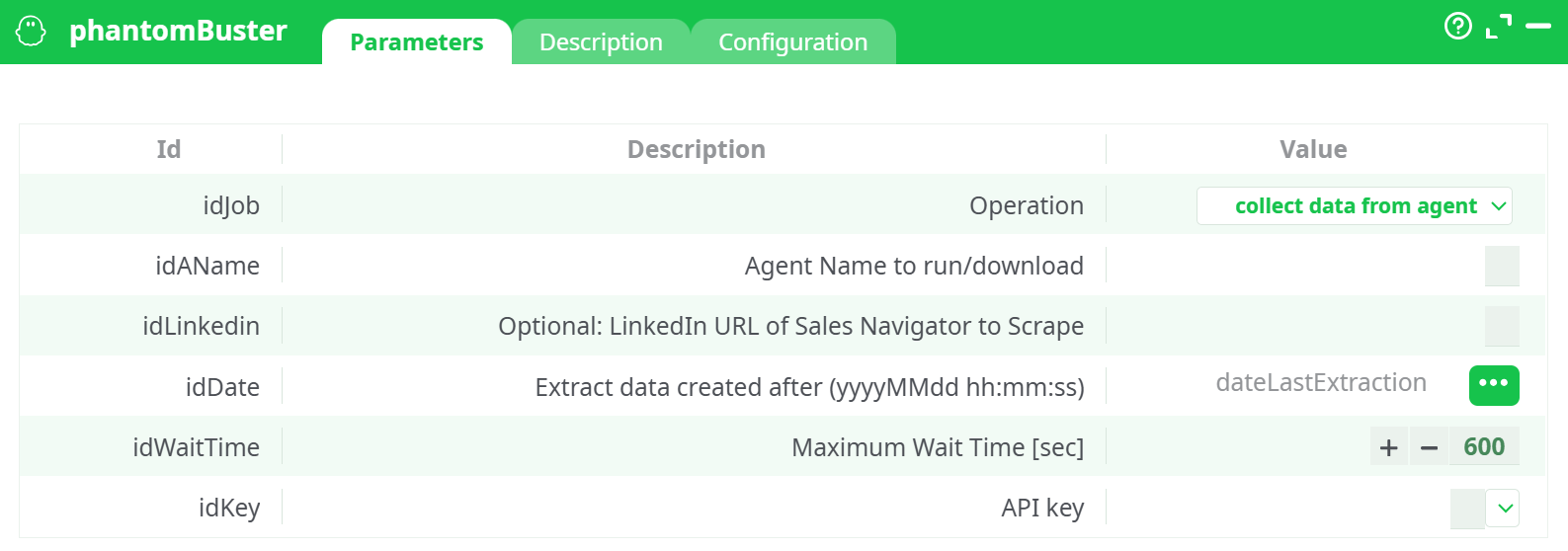
Parameters:
- Operation
- Agent Name to run/download
- (optional)LinkedIn URL of Sales Navigator to Scrape
- Extract data created after (yyyyMMdd hh:mm:ss)
- Maximum Wait Time (sec)
- API key
¶ Description tab
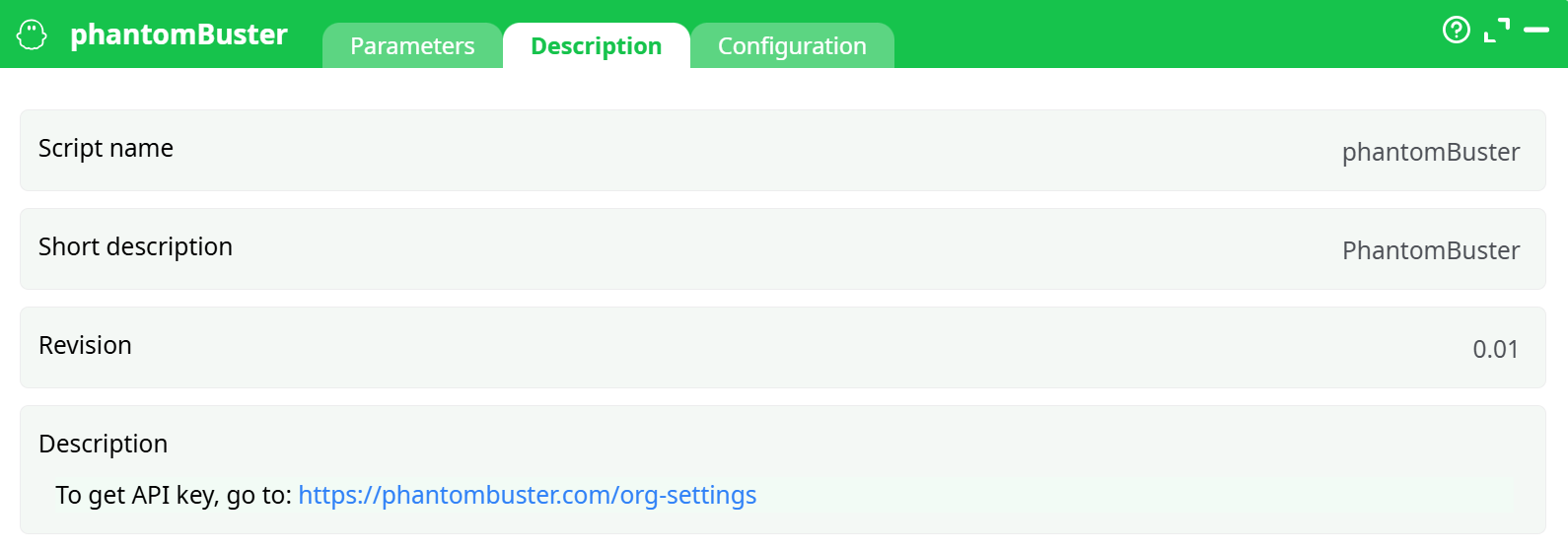
Parameters:
- Script name
- Short description
- Revision
- Decription
¶ Configuration tab
See dedicated page for more information.
¶ About
This action lets you control PhantomBuster agents from a pipeline and (optionally) download their results.
Typical uses:
- Run a PhantomBuster agent (e.g., LinkedIn Sales Navigator search, profile/companies scrapers).
- Wait for the run to finish (with a safety timeout).
- Fetch the latest dataset produced by an agent, optionally only the data created after a given timestamp (incremental loads).
Please ensure your usage complies with PhantomBuster’s Terms and with the target website’s terms (e.g., LinkedIn). Use dedicated accounts/proxies when required.
¶ Getting the API key
- Log in to PhantomBuster.
- Go to Settings → API key.
- Copy the key and paste it into API key.
¶ Operations & outputs
¶ 1) list All Agents
- What it does: Reads your account’s agents (id, name, status, last run info, etc.).
- Output: One row per agent with basic metadata.
¶ 2) run agent
- What it does: Triggers a run for Agent Name to run/download (uses Optional: LinkedIn URL of Sales Navigator to Scrape if the agent expects a URL input).
- Output: A small table with the launch/run identifiers and initial status.
¶ 3) run agent + wait
- What it does: Triggers the run then waits up to Maximum Wait Time [sec] seconds for completion.
- Output: Final run status (success/failed/timeout) and run identifiers.
¶ 4) run agent + wait + collect data
- What it does: Triggers the run, waits up to Maximum Wait Time [sec], then downloads the resulting dataset.
- Output: The agent’s dataset, optionally filtered by Extract data created after (yyyyMMdd hh:mm:ss) (if provided).
¶ 5) collect data from agent
- What it does: Downloads the latest dataset produced by Agent Name to run/download without starting a new run.
- Output: The agent’s dataset, optionally filtered by Extract data created after (yyyyMMdd hh:mm:ss) (if provided).
Filtering with
Extract data created after (yyyyMMdd hh:mm:ss)
When provided, rows withcreatedAt(or the agent’s equivalent timestamp) strictly afterExtract data created after (yyyyMMdd hh:mm:ss)are returned. The time is interpreted as UTC.
¶ Typical setups
¶ A) One-shot download of the latest data
- Operation:
collect data from agent - Agent Name to run/download: your agent name (exact match)
- Extract data created after (yyyyMMdd hh:mm:ss): leave empty (full dataset)
- API key: your API key
Run the box → you get the most recent dataset produced by the agent.
¶ B) Fully automated refresh (run → wait → fetch)
- Operation:
run agent+wait+collect data - Agent Name to run/download: your agent name
- Optional: LinkedIn URL of Sales Navigator to Scrape: (only if your agent expects a Sales Navigator URL)
- Maximum Wait Time [sec]: e.g.,
600 - Extract data created after (yyyyMMdd hh:mm:ss): point it to a pipeline column (e.g.,
dateLastExtraction) for incremental loads - API key: your API key
To supply
Extract data created after (yyyyMMdd hh:mm:ss)from upstream, connect a small table with a column (e.g.,dateLastExtraction) and pick it in the selector. The screenshot shows exactly this pattern.
¶ Notes & best practices
- Time zone: PhantomBuster APIs and many agents use UTC timestamps. Provide
Extract data created after (yyyyMMdd hh:mm:ss)in UTC to avoid gaps/overlaps. - Incremental loads: Store the max createdAt you consumed and feed it back into
Extract data created after (yyyyMMdd hh:mm:ss)next run. - Wait time vs. plan limits: If the agent often exceeds
Maximum Wait Time [sec], either raise the value or switch to “run agent” followed by a later “collect data from agent.” - LinkedIn URL: Only relevant for LinkedIn agents that accept a Sales Navigator URL; otherwise leave it blank.
- Security: Keep API key in a secret; avoid logging it or saving it in plain text.
- Rate limits / daily minutes: Respect your PhantomBuster plan limits. Stagger runs if needed.
¶ Output schema
Because each PhantomBuster agent can output different fields, the box returns whatever the agent produced (CSV/JSON converted to rows/columns). Common columns include identifiers, URLs, names, titles, company, and timestamps such as createdAt. Use downstream steps to normalize/rename columns as needed.
