¶ Description
Reads a table from a file where each column has a constant-width (i.e. a “square” file).
¶ Parameters

Parameters:
- Input file Path to the file containing the data.
- Data Definition String Comma-separated list of column widths in bytes
- The first line of the file contains the column names If enabled, uses the first line as the header row.
- drop last column If enabled, drops the last column from the output.
- Ignore BOM (Byte-Order-Mask) Header Skips the BOM header if it exists in the file.
- file encoding Character encoding used to read the file. Example:
Latin1,UTF-8,EBCDIC. - Minimum input buffer size Sets the minimum memory buffer size for file reading (in MB).
¶ About
Reads a table from a file where each column has a constant width (i.e., a fixed-width or square file).
Each column’s width is specified by the user in bytes (characters), making this action ideal for parsing legacy or fixed-layout files.
In fixed-width files:
- Each column has a predefined width, measured in bytes or characters.
- Columns are aligned by position, not by delimiters like commas or tabs.
- This format is common in legacy systems, mainframe exports, and financial or government reports.
¶ Key Features:
- Reads files with consistent column widths.
- Supports a wide range of encodings (e.g.,
Latin1,UTF-8,EBCDIC). - Optionally uses the first row as column headers.
- Can ignore BOM headers automatically.
- Allows dropping the last column if it contains padding or unnecessary data.
- Optimized for large files with adjustable buffer size for performance tuning.
¶ Why Use This Action:
- Essential for working with legacy data formats.
- Allows reliable extraction of structured data without needing delimiters.
- Helps migrate, analyze, or integrate old datasets into modern pipelines.
¶ Common Sources of Fixed-Width Files:
- COBOL, mainframe, and AS400 systems.
- Banking and financial transaction logs.
- Government census and tax datasets.
- Telecom equipment logs or industrial reports.
- Exported reports from ERP or legacy accounting systems.
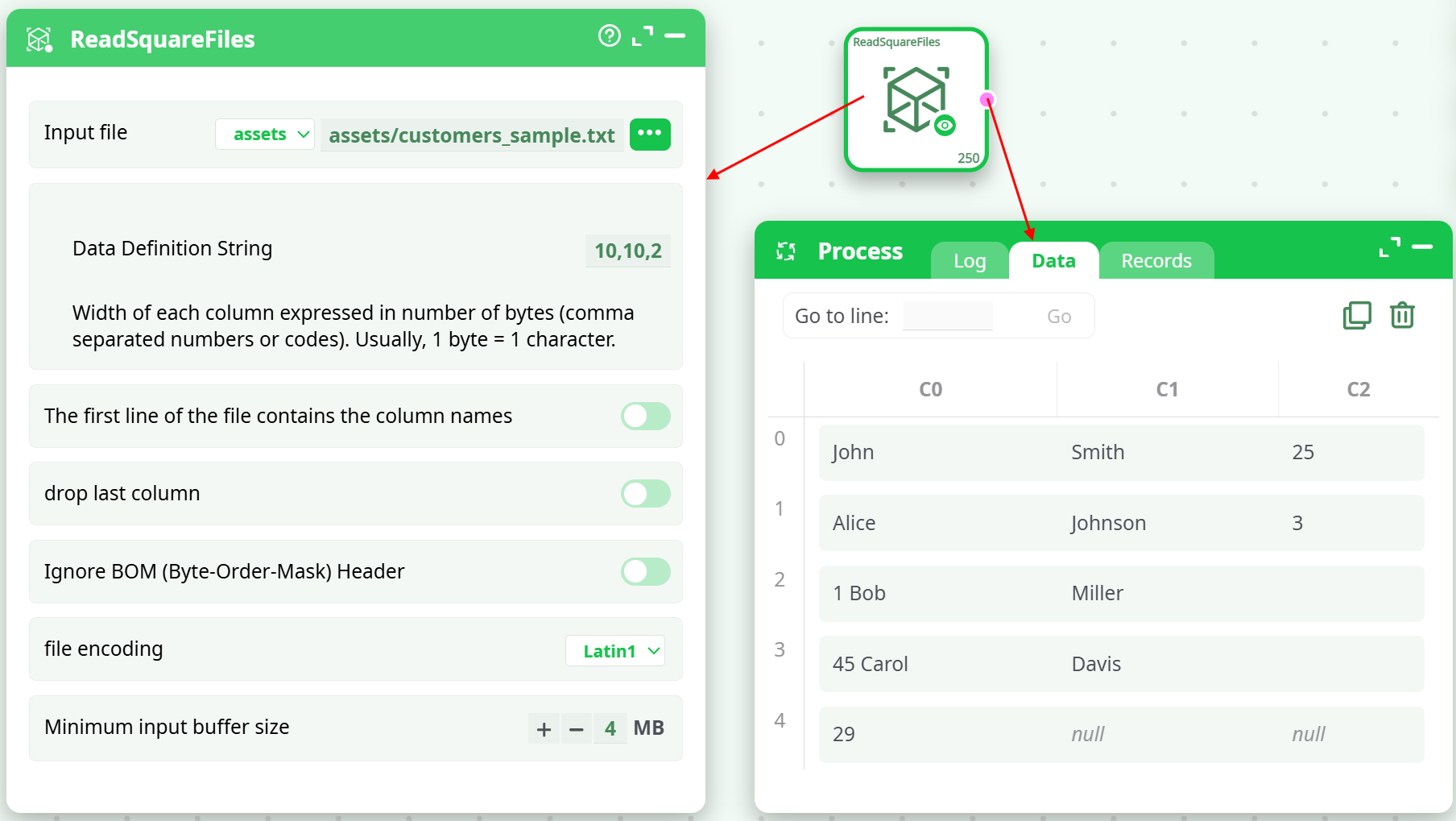
¶ Example Input File (customers_sample.txt)
| John | Smith | 25 |
| Alice | Johnson | 31 |
| Bob | Miller | 45 |
| Carol | Davis | 29 |
¶ Example Settings
- Input file:
assets/customers_sample.txt - Data Definition String:
10,10,2 - First line contains column names: Disabled
- Drop last column: Disabled
- Ignore BOM: Disabled
- File Encoding:
Latin1 - Minimum Input Buffer Size:
4 MB
¶ Example Output
¶ Use Cases
¶ ✅ 1. Importing Legacy System Data
Many legacy systems (e.g., mainframes, COBOL apps) export datasets as fixed-width files.
This action allows you to load such data into modern pipelines for analysis or migration.
¶ ✅ 2. Reading Bank Statements or Financial Reports
Banks and financial institutions often use fixed-width formats for printable reports.
This tool lets you load those reports for auditing, reconciliation, or further processing.
¶ ✅ 3. Processing Government Data Feeds
Government agencies often provide census data, tax files, or reports in fixed-width formats.
You can use this action to parse such datasets for compliance, analytics, or storage.
¶ ✅ 4. Parsing Industrial or Device Logs
Many telecom devices or industrial systems output logs in fixed-width layouts.
This tool helps load and parse these logs for monitoring, alerts, or diagnostics.
¶ ✅ 5. Preprocessing Data for Machine Learning
Legacy structured data can be standardized using this action before using it for Machine Learning or advanced analytics.
Notes
- Works best with monospaced fonts and reports exported by legacy systems.
- Ideal for workflows needing reliable parsing without delimiters.
- Supports BOM handling and various encodings.
