¶ Description
Compute normalized mutual information.
¶ Parameters
¶ Parameters tab
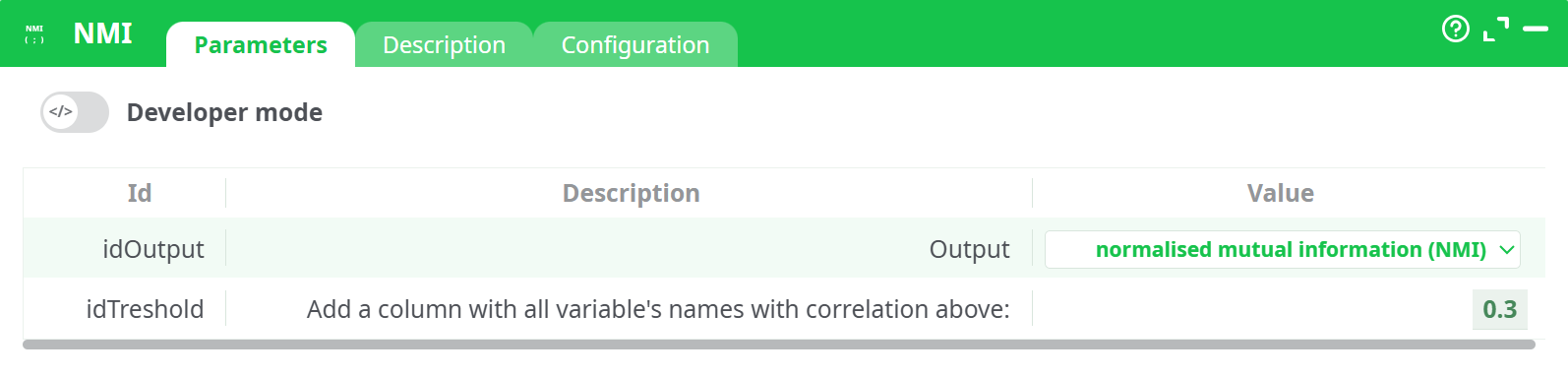
Parameters:
- Output
- Add a column with all variable's names with correlation above:
¶ Description tab
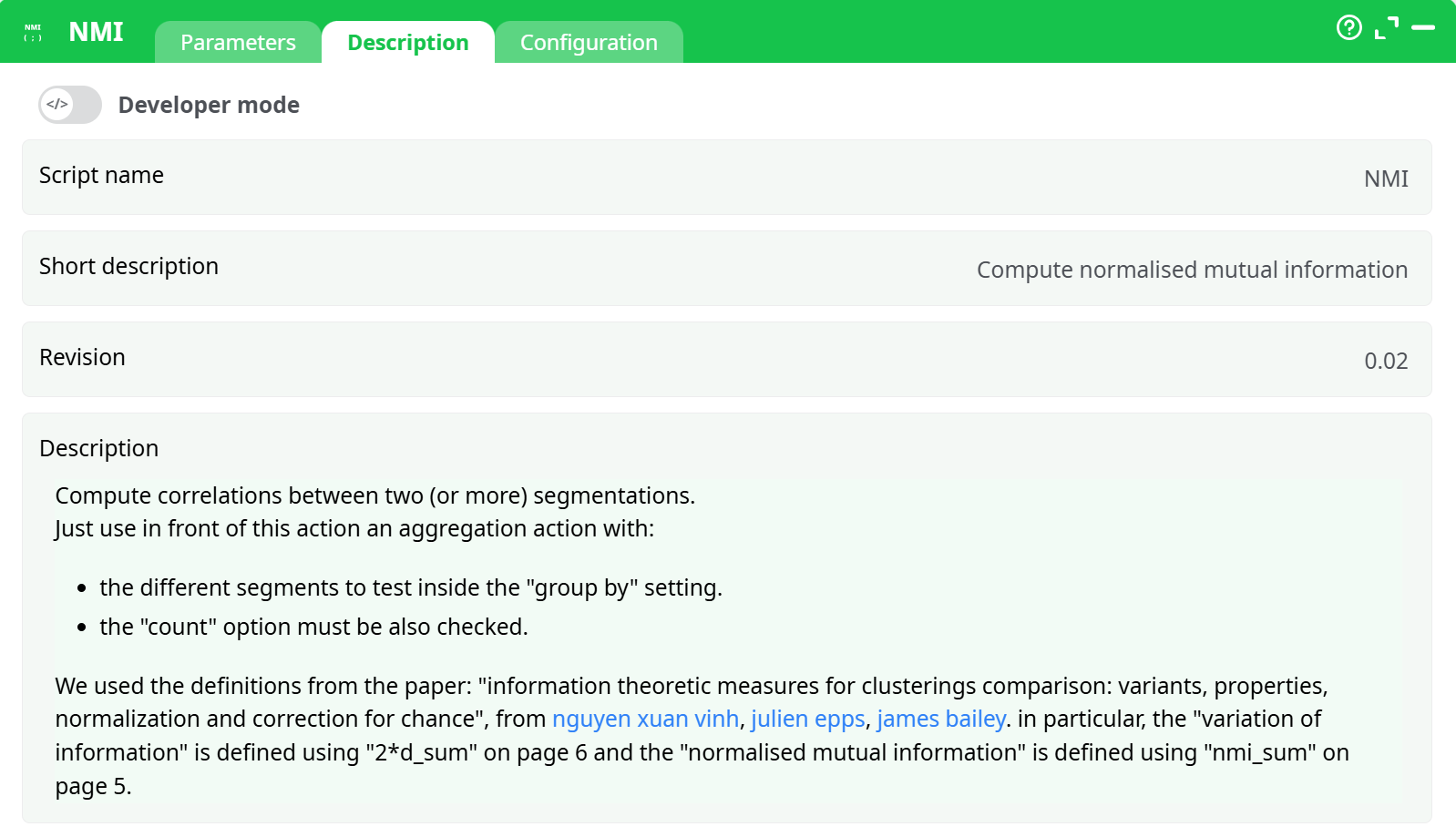
Parameters:
- Script name
- Short description
- Revision
- Decription
¶ Configuration tab
See dedicated page for more information.
¶ About
The NMI (Normalised Mutual Information) action computes correlations between two or more segmentations using information-theoretic measures.
It supports two types of correlation metrics:
- Normalised Mutual Information (NMI)
- Variation of Information (VI)
This action is particularly useful for analyzing clustering or segmentation similarity.
¶ Key Features
- Computes correlation between multiple segmentations.
- Supports two output measures:
- Normalised Mutual Information (NMI)
- Variation of Information (VI)
- Allows filtering correlated variables based on a threshold.
¶ Typical Workflow
- Load your dataset (e.g., using readCSV).
- Apply an aggregate action to group and count segment combinations.
- Connect the NMI action after the aggregate action to compute correlations.
Note:
The aggregate action must:
- Use segment columns inside the Group by setting.
- Enable the count non-NULL option for correct NMI computation.
¶ Example Pipeline
¶ Example Input Dataset
| CustomerID | SegmentA | SegmentB |
|---|---|---|
| 1 | Group1 | Group2 |
| 2 | Group1 | Group2 |
| 3 | Group2 | Group1 |
| 4 | Group2 | Group2 |
| 5 | Group1 | Group1 |
| 6 | Group2 | Group2 |
| 7 | Group1 | Group1 |
| 8 | Group2 | Group2 |
| 9 | Group1 | Group1 |
| 10 | Group2 | Group2 |
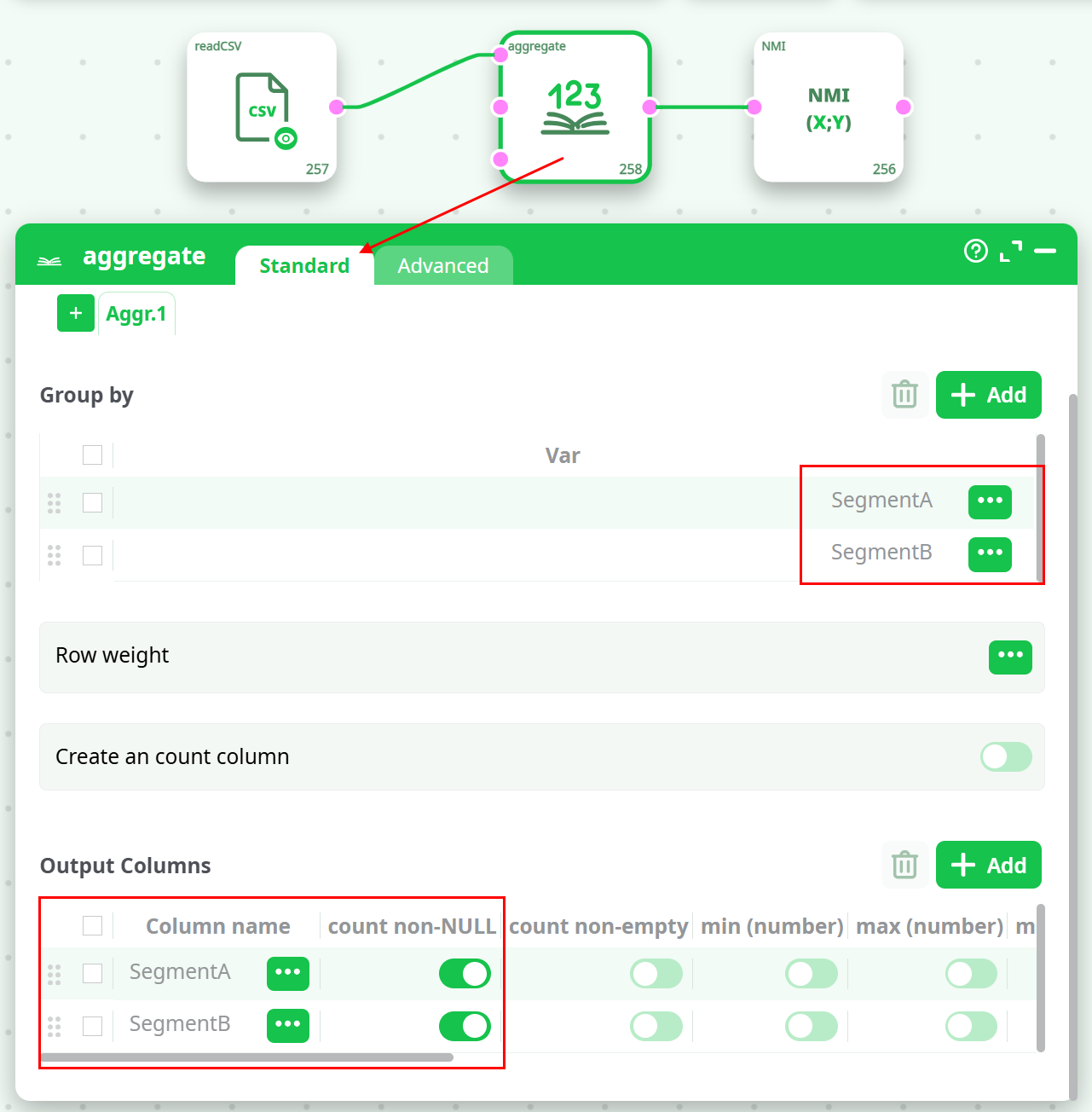
¶ Aggregate Action Settings
- Group By:
SegmentASegmentB
- Output Columns:
- Enable count non-NULL for both SegmentA and SegmentB.
¶ NMI Action Settings
| Parameter | Description | Example Value |
|---|---|---|
| Output | Choose the metric for computation | normalised mutual information (NMI) or variation of information |
| Threshold (idTreshold) | Add a column with variables whose correlation exceeds this threshold | 0.3 |
¶ 
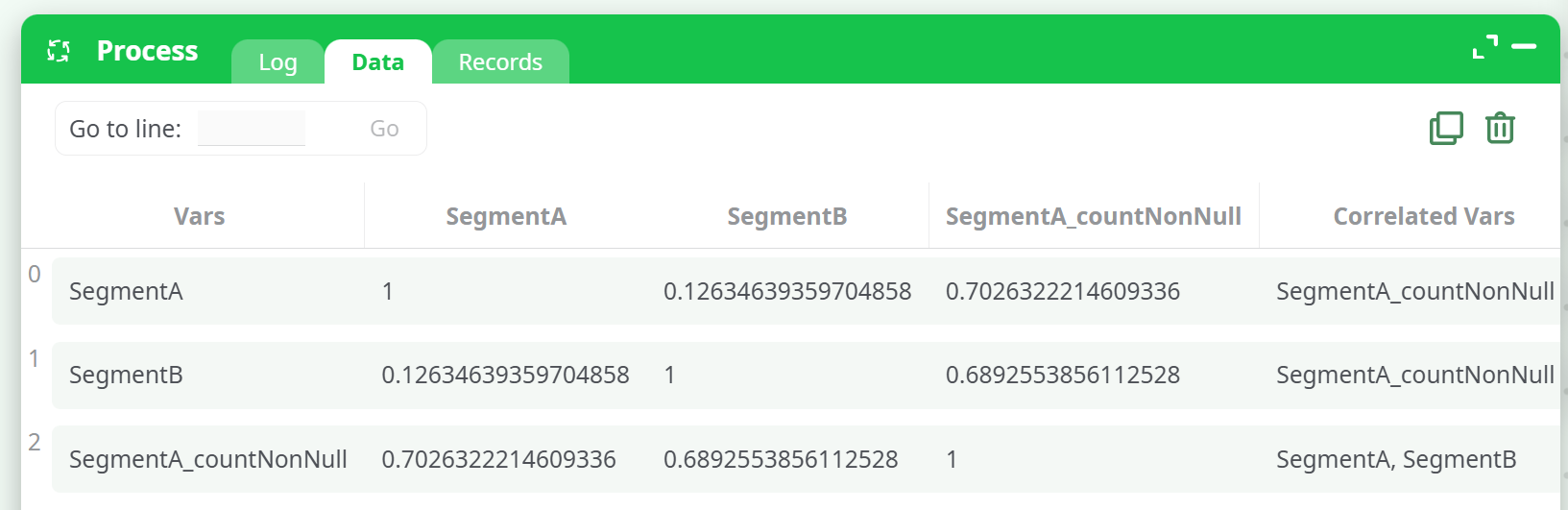
¶ Example Output: NMI Mode
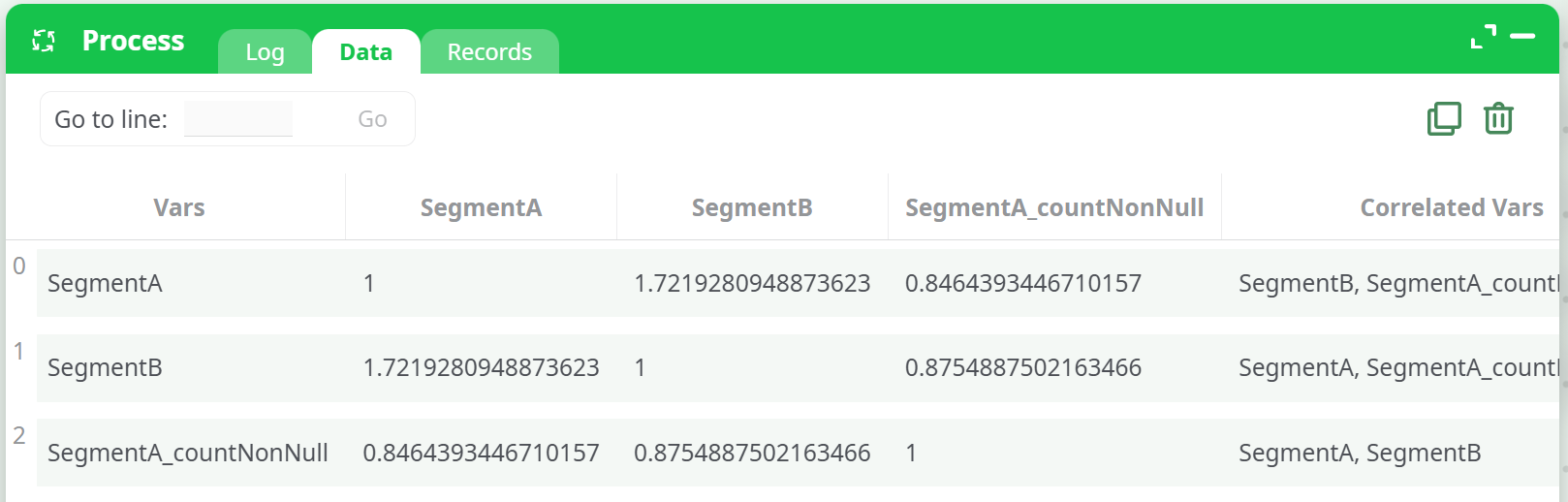
¶ Example Output: Variation of Information Mode
¶ Description Tab Text (from UI)
Compute correlations between two (or more) segmentations.
Just use in front of this action an aggregation action with:
- the different segments to test inside the "group by" setting.
- the "count" option must also be checked.
Definitions are based on the paper:
"Information Theoretic Measures for Clusterings Comparison: Variants, Properties, Normalization and Correction for Chance"
by Nguyen Xuan Vinh, Julien Epps, and James Bailey.
Notes
- This action requires a properly grouped and counted dataset from an aggregate action.
- Commonly used in segmentation analysis, clustering, and ML pipelines.
- Higher NMI = stronger correlation; Lower VI = stronger similarity.
