¶ Description
Identifies outliers in a dataset.
¶ Parameters
¶ Parameters tab
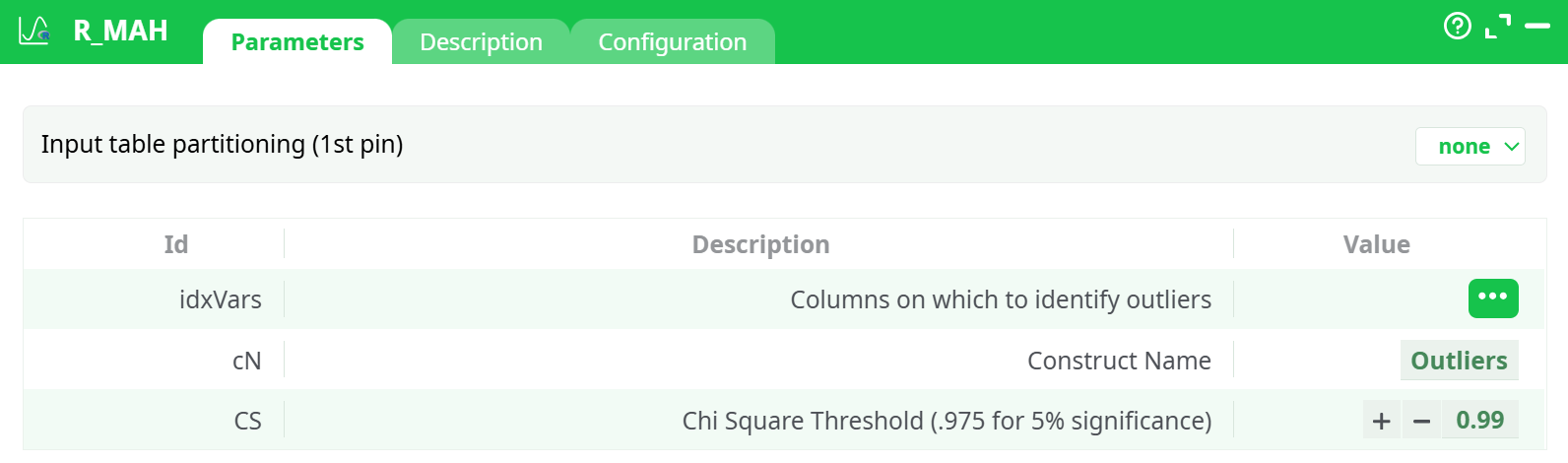
Parameters:
- Columns on which to identify outliers
- Construct Name
- Chi Square Threshold (.975 for 5% significance)
¶ Description tab

Parameters:
- Script name
- Short description
- Revision
- Decription
¶ Configuration tab
See dedicated page for more information.
¶ About
R_MAH identifies multivariate outliers in a dataset using the Mahalanobis distance and a Chi-square significance threshold.
Unlike univariate rules (e.g., z-score on a single column), Mahalanobis distance measures how far each record lies from the multivariate center of the selected variables while taking into account their covariance structure. This means it:
- Flags points that are unusual given the joint behavior of the variables (e.g., a normal value in column A can still be an outlier when combined with a value in column B).
- Is scale-invariant (it uses the inverse covariance matrix), so you can analyze variables in different units without manual normalization.
- Produces a positive, continuous score per row (the distance), which is then compared to a Chi-square critical value; if the distance exceeds that threshold, the row is marked as an outlier.
¶ Statistical background (high level)
- For a vector of features and the dataset mean with covariance , the squared Mahalanobis distance is:
. - Under the assumption of a (approximately) multivariate normal distribution, follows a Chi-square distribution with degrees of freedom equal to the number of selected variables.
- R_MAH compares each row’s to a Chi-square quantile (configurable). Values above the quantile are flagged as outliers.
Partitioning note
In many real-world datasets, “outliers” only make sense within a segment (by product line, region, customer cohort, etc.). R_MAH supports partitioned execution so the distance is computed independently per group, preventing global patterns from hiding local anomalies. Ensure the data is sorted by the partition key when you use column-based partitioning.
¶ What the action expects
- Tabular input where the selected columns are numeric and contain no non-numeric or constant values.
- Sufficient row count for a stable covariance estimate (rule of thumb: at least 5–10× as many rows as variables selected).
¶ Outputs
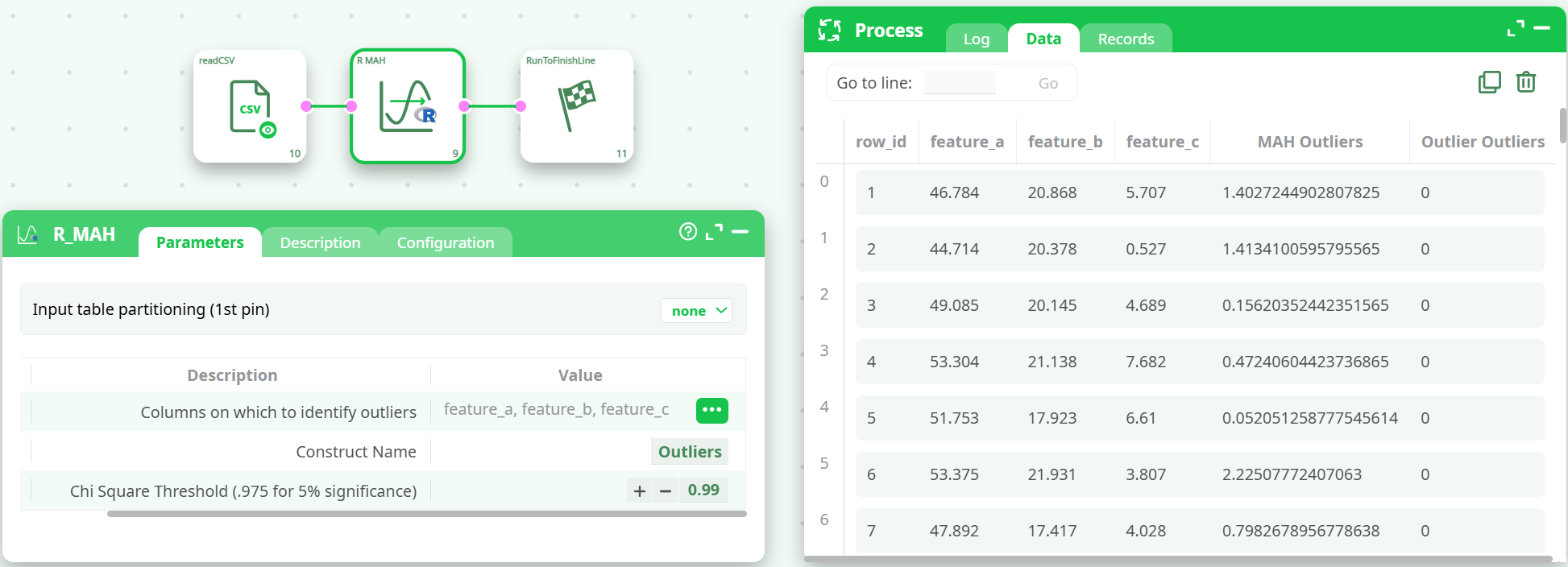
R_MAH enriches the input table with:
MAH Outliers— the Mahalanobis distance (or squared distance, depending on implementation) for each row based on the selected feature set.Outlier Outliers— an indicator (0/1) showing whether the row is flagged as an outlier given the selected Chi-square threshold.
These columns appear alongside the original input columns and can be forwarded to downstream actions (filtering, labeling, exporting, etc.).
¶ Parameters
| Section / Id | UI label | What it does | Notes & tips |
|---|---|---|---|
| Partitioning (top of panel) | none / by column / fixed number of lines (excluding last) | Controls how the input is split before computing distances. | Use by column to compute outliers per group (e.g., per category). Make sure the dataset is sorted by the partition column upstream. |
idxVars |
Columns on which to identify outliers | The numeric variables used to compute Mahalanobis distances. | Choose only numeric, non-collinear columns. Remove IDs or near-constant fields; they destabilize the covariance matrix. |
cN |
Construct Name | Base name for the computed fields. | Default is Outliers. Downstream columns will use this base (e.g., MAH Outliers, Outlier Outliers). |
CS |
Chi Square Threshold (.975 for 5% significance) | The quantile of the Chi-square distribution used for flagging. | Typical values: 0.975 (~5% one-sided), 0.99, 0.999. Higher values → fewer, more severe outliers. Lower values → more outliers. |
¶ Minimal run (quick start)
-
Connect input to R_MAH (e.g., from a CSV reader).
-
Open Parameters:
- Columns on which to identify outliers (
idxVars): pick the numeric features to analyze. - Construct Name (
cN): keep default or provide a label (e.g., Outliers). - Chi Square Threshold (
CS): keep 0.99 (as shown) or set to your desired sensitivity. - (Optional) Partitioning: leave none for whole-table analysis, or choose by column and select your grouping field upstream.
- Columns on which to identify outliers (
-
Run the pipeline.
-
Inspect the Data tab: you’ll see
MAH Outliers(distance) andOutlier Outliers(0/1 flag). -
(Optional) Filter rows where
Outlier Outliers = 1for review, remediation, or downstream routing.
¶ Interpretation & recommended practice
-
Distance scale: Larger
MAH Outliersvalues indicate more extreme observations. Use the binary flag for primary decisions and the distance for ranking. -
Threshold tuning: Start with 0.99. If you get too many false positives, raise it (e.g., 0.995/0.999). If you miss anomalies, lower it (e.g., 0.975).
-
Feature hygiene:
- Remove perfectly collinear or near-collinear variables (they make unstable).
- Impute or drop rows with missing values in selected variables.
- Standardization is usually unnecessary, but you may standardize if variables have extreme scale disparities and covariance estimation is noisy.
-
Segmented detection: Prefer partitioned runs when business logic is segment-dependent (e.g., “expensive” only within a product tier).
-
Post-processing: Combine the outlier flag with domain rules (capacity limits, business constraints) before taking automated actions.
¶ Troubleshooting
-
All distances are 0 or NA
- Check for constant columns or identical rows.
- Ensure all selected variables are numeric.
-
Many rows flagged unexpectedly
- Raise
CSto a stricter value (e.g., 0.995 or 0.999). - Inspect variables for skew/heavy tails; consider transforming them (log for positive variables) upstream.
- Raise
-
“Singular matrix / covariance not invertible” (if shown in logs)
- Drop collinear variables, reduce the feature count, or increase sample size.
- Remove exact duplicates if present.
-
Segment-wise behavior missing
- Enable Partitioning (by column) and ensure upstream sort by the partition field.
¶ Operational notes
- Performance: Complexity grows with the number of variables (covariance inversion) and rows. For very wide tables, prefer a smaller, well-chosen feature set.
- Reproducibility: Keep a stable preprocessing chain (imputation, filtering, transformations) before R_MAH so thresholds are comparable run-to-run.
- Governance: Save the Construct Name and parameter set in your pipeline description for auditability.
¶ Summary
R_MAH provides a robust, statistically grounded way to detect multivariate anomalies. By leveraging Mahalanobis distance and a configurable Chi-square threshold—plus optional partitioned execution—it surfaces records that don’t fit the joint distribution of your chosen features. Use the distance to rank anomalies and the binary flag to act on them, adjusting sensitivity with the threshold and grouping strategy to match your business context.
