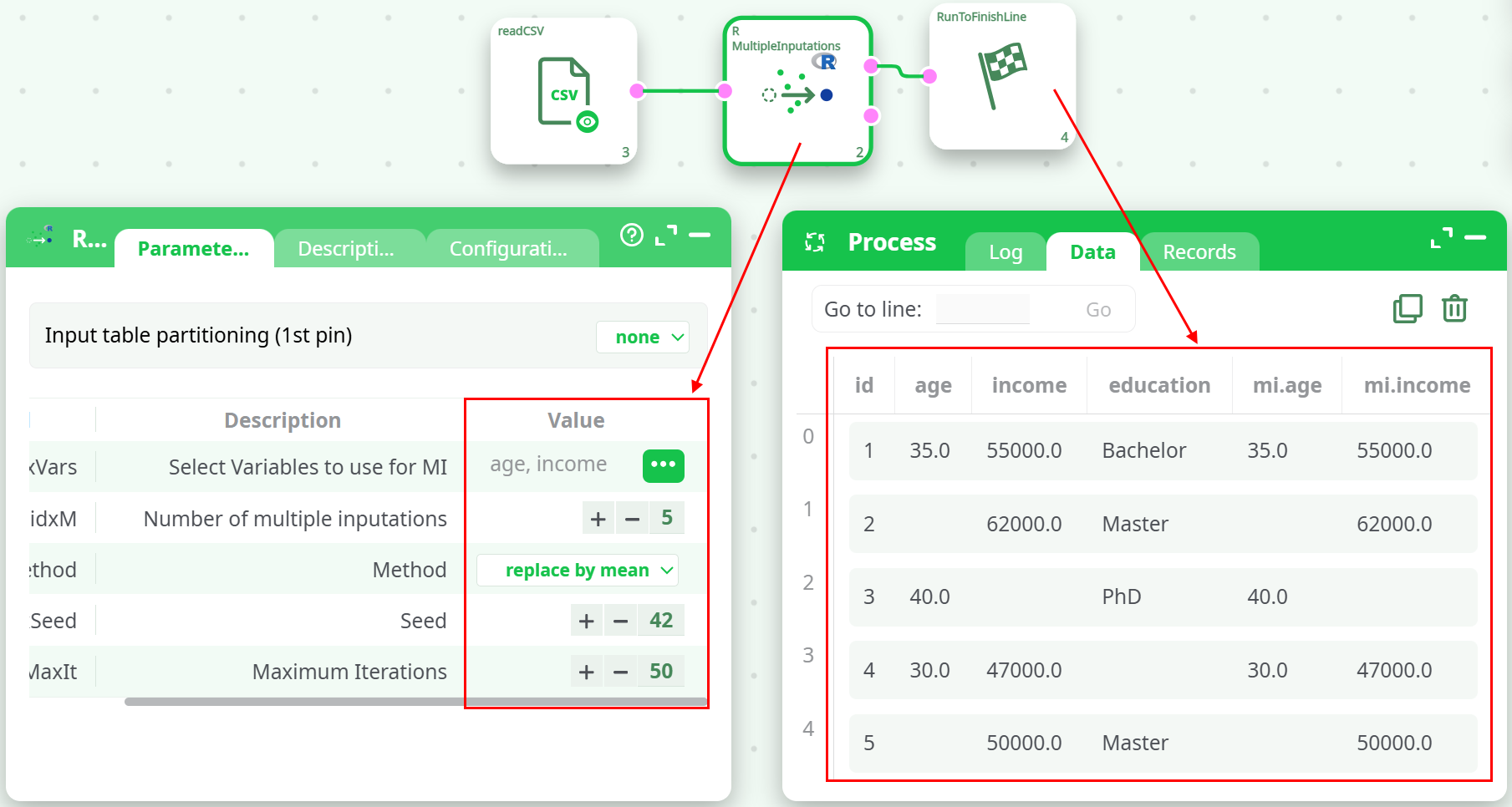
¶ Description
Multiple inputations.
¶ Parameters
¶ Parameters tab

Parameters:
- Select Variables to use for MI
- Number of Multiple Inputations
- Method
- Seed
- Maximum Iterations
¶ Description tab
See dedicated page for more information.
¶ Configuration tab
See dedicated page for more information.
¶ About
The R_MultipleImputations action button handles missing data in tabular datasets using Multiple Imputation by Chained Equations (MICE). This advanced statistical method generates multiple plausible datasets with imputed values to improve the reliability of downstream analyses.
¶ Use Cases
- Preparing datasets for machine learning or statistical models that cannot handle missing values.
- Reducing bias by applying multiple imputations instead of single-value imputation.
- Preserving variability and structure in datasets with partial missingness.
¶ How It Works
The action uses the mice R package to generate several imputed versions of the original dataset. It creates these by iteratively modeling each variable with missing data as a function of other variables. This method captures the uncertainty of the imputed values and maintains the relationships in the data.
¶ Input Requirements
- A table in which at least one column contains missing values.
- Missing values should be denoted by
NA, blank, or empty cells. - The table may include both numeric and categorical columns.
- Columns with all missing values will be ignored.
¶ Parameters
| Parameter | Type | Description |
|---|---|---|
Columns to impute |
List | Specify the columns to be imputed. If empty, all columns with missing values will be imputed. |
Number of imputed datasets |
Integer | The number of separate imputations to create (m). Default: 5. |
Maximum iterations |
Integer | Maximum number of iterations used to build the imputation model. Default: 5. |
Method |
String | Optional: Force a specific imputation method for all columns (e.g., pmm, norm, logreg). Leave blank to auto-select based on data type. |
Seed |
Integer | Optional: Random seed for reproducibility of results. |
¶ Input Example
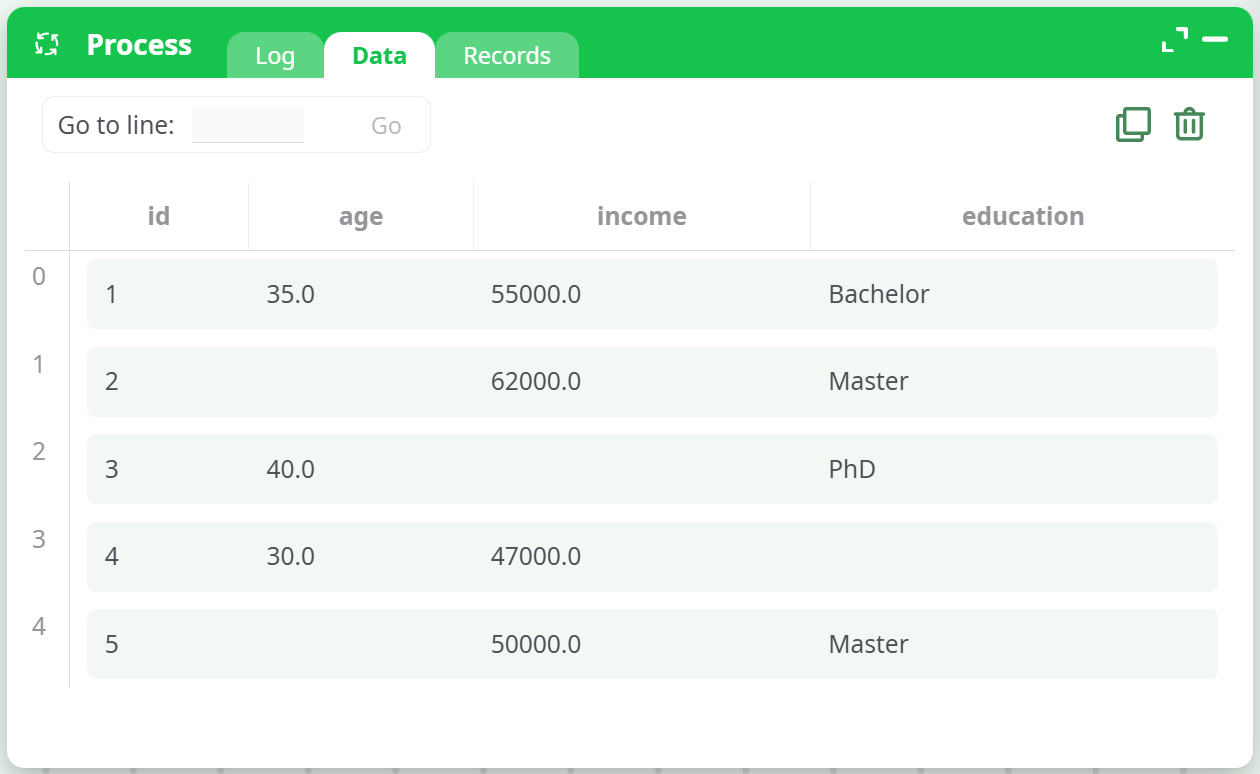
✅ Missing values should be visible in the selected columns to observe the effect of the imputation.
¶ Output
- A table with the imputed values replacing the missing entries.
- If
m > 1, the result will contain multiple rows for each original row, identified using the.impcolumn.
¶ Output Example
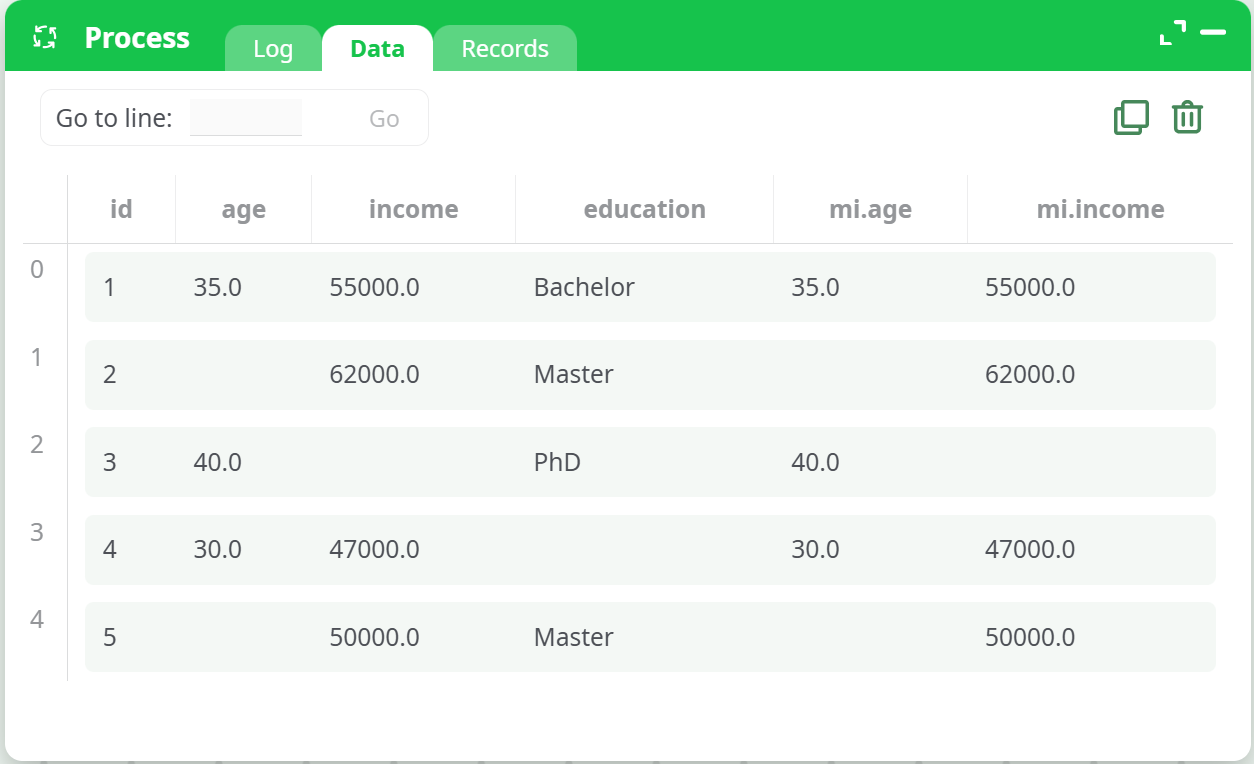
Each row of the output belongs to one of the multiple imputations, and the .imp column indicates which imputation set it belongs to.
¶ Troubleshooting
- Columns with all values missing cannot be imputed and may be dropped.
- For categorical variables, use methods like
logreg(binary) orpolyreg(polytomous). - Ensure column data types are consistent; mixed types in a column can cause failure.
- Avoid setting
mtoo low — usem = 5or more for statistically robust results.
