¶ Description
Text similarity computation.
¶ Parameters
¶ Parameters tab
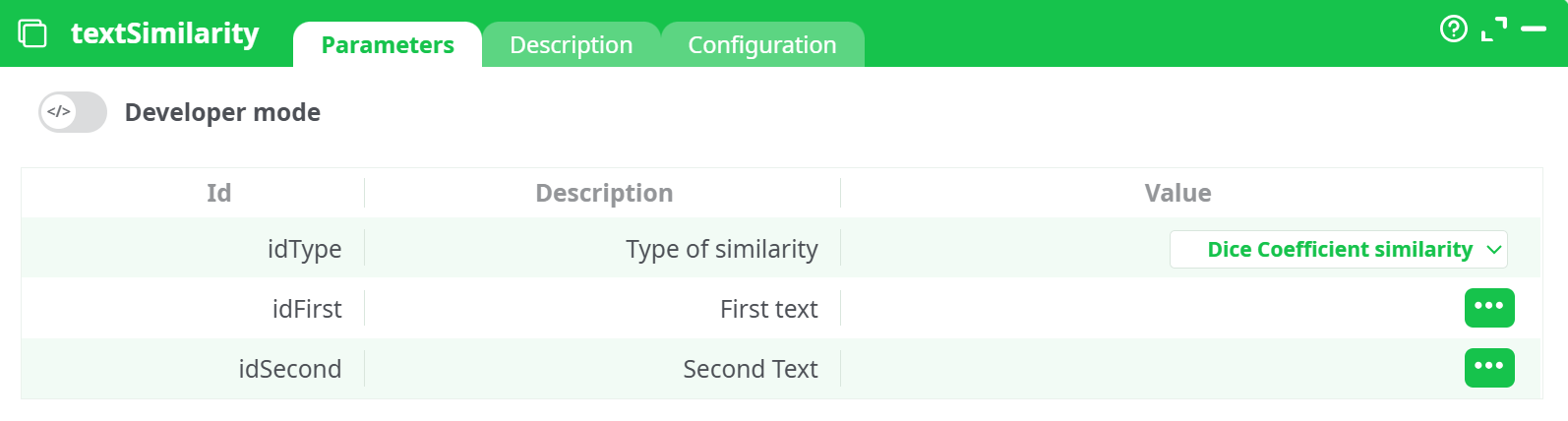
Parameters:
-
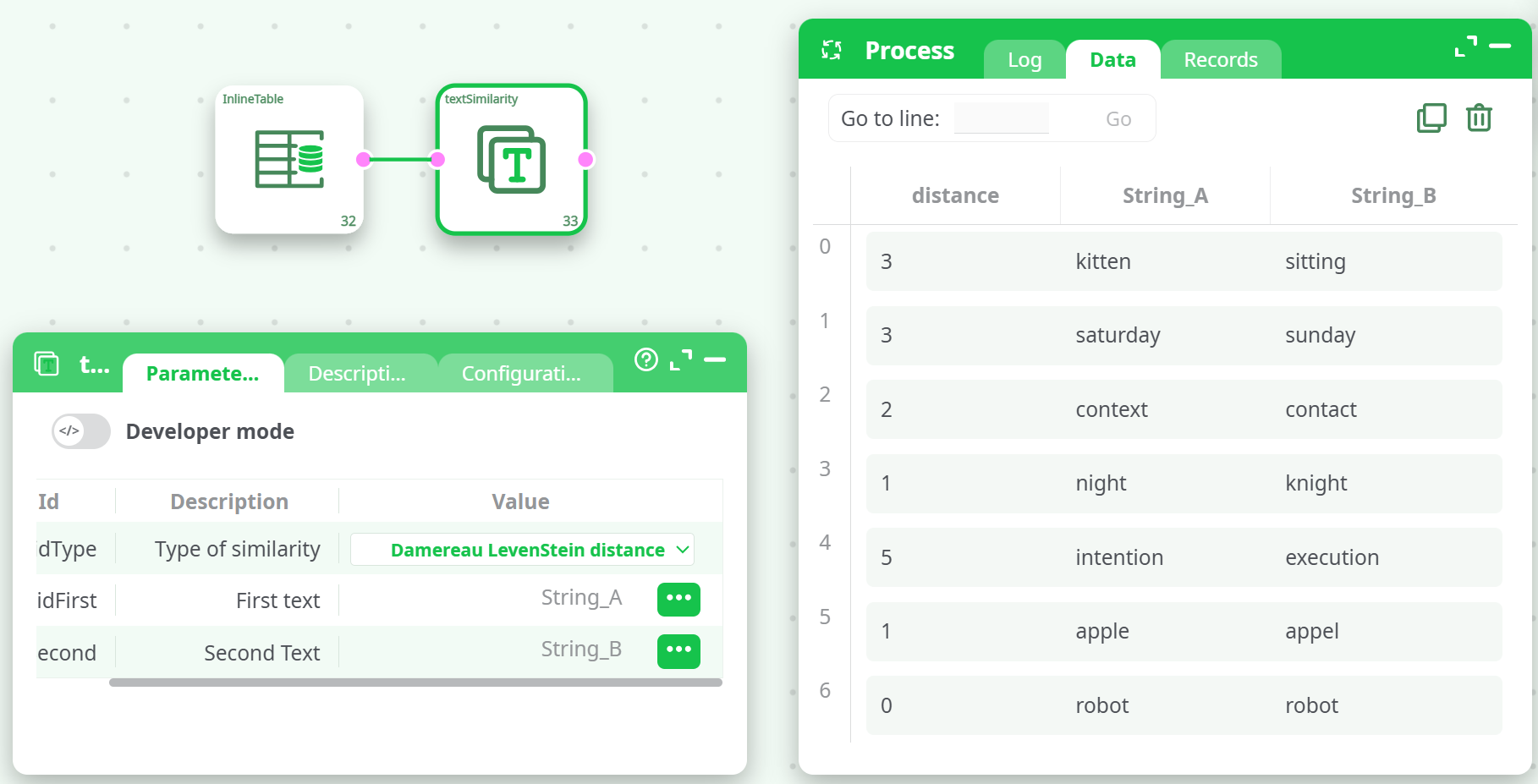
Type of similarity
Selects the algorithm used to compute similarity:Damereau LevenStein similarity: Measures how similar two strings are by counting insertions, deletions, substitutions, and transpositions.Jaro Winkler similarity: Emphasizes similarity at the beginning of the strings, useful for matching names.Dice Coefficient similarity: Based on bigram overlap between the two strings.Damereau LevenStein distance: Returns the distance (not similarity), i.e., the number of edits.
-
First text
Column containing the first string to compare. -
Second Text
Column containing the second string to compare.
¶ Description tab
See dedicated page for more information.
¶ Configuration tab
See dedicated page for more information
¶ About
The Text Similarity action calculates a similarity score or distance between two strings using selected string matching algorithms. This is commonly used in data cleaning, deduplication, or approximate string matching tasks.
¶ Output
- A new column is created with similarity scores (values between 0 and 1) or distance (integer), depending on the selected algorithm.
- Column name is based on the selected algorithm and input names.
¶ Tips
- Use
Damereau LevenStein similarityfor general fuzzy matching tasks. - Prefer
Jaro Winklerwhen comparing short strings or names. Dice Coefficientworks well for linguistic similarity based on shared parts.- If you need an actual count of differences, choose
Damereau LevenStein distance.
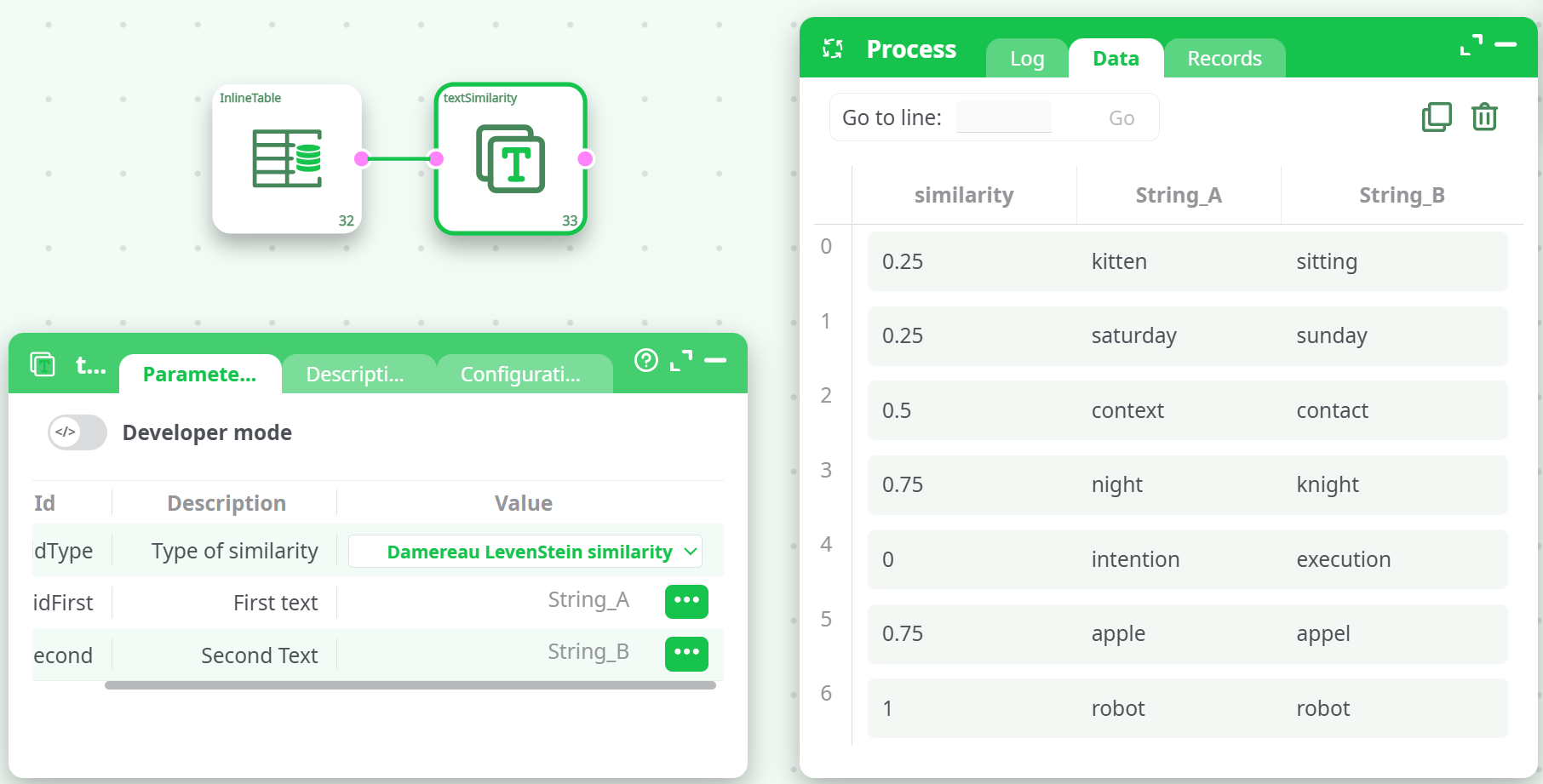
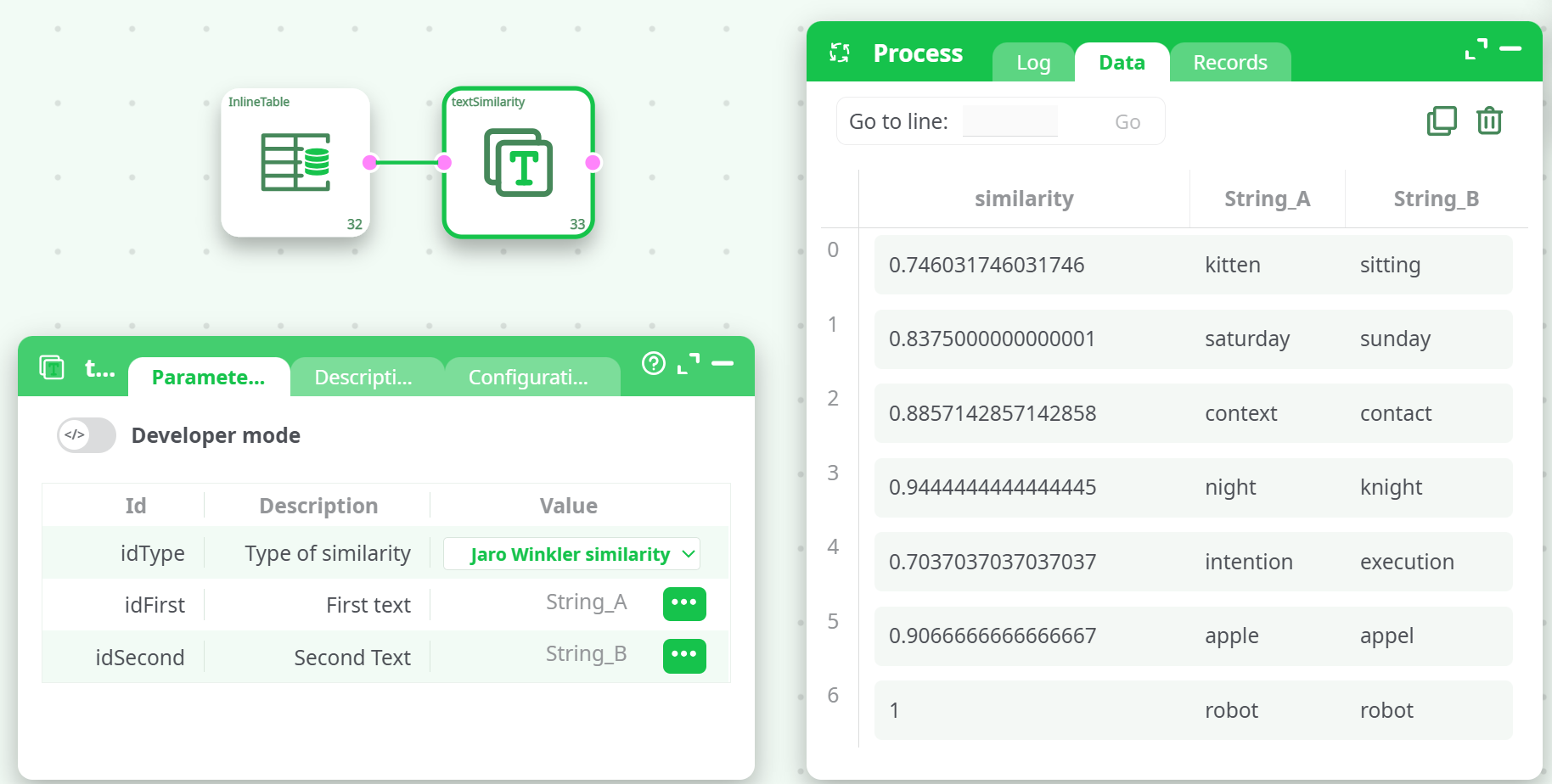
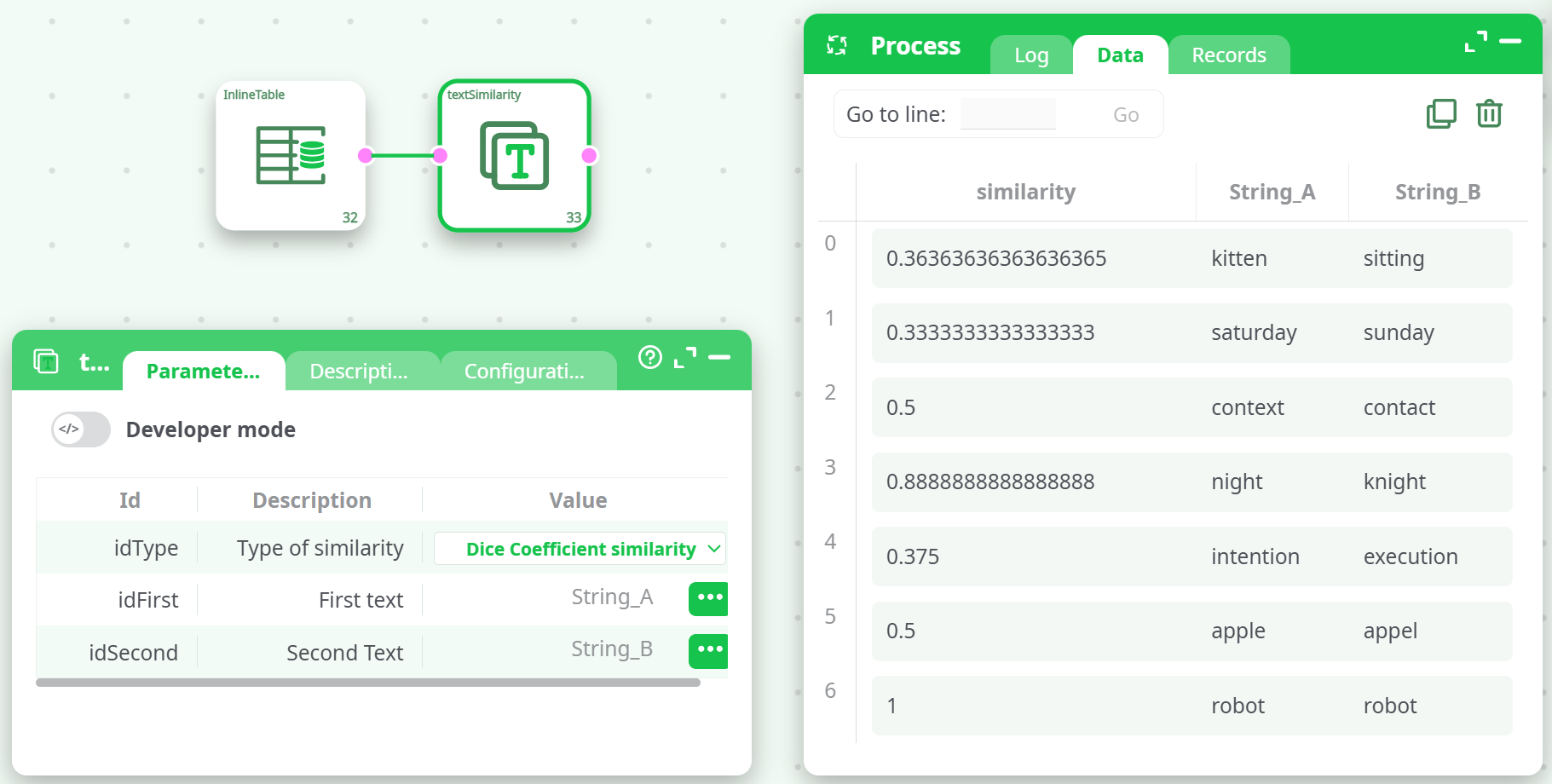
¶ Example Input
| String_A | String_B |
|---|---|
| kitten | sitting |
| saturday | sunday |
| context | contact |
| night | knight |
| intention | execution |
| apple | appel |
| robot | robot |
¶ Sample Output (Damereau LevenStein similarity)
¶ Sample Output (Jaro Winkler similarity)
¶ Sample Output (Dice Coefficient similarity)
¶ Sample Output (Damereau LevenStein distance)
See CorrectSpelling action documentation for more information on the topic.
