¶ Description
Frequency table for each word in input.
¶ Parameters
¶ Parameters tab
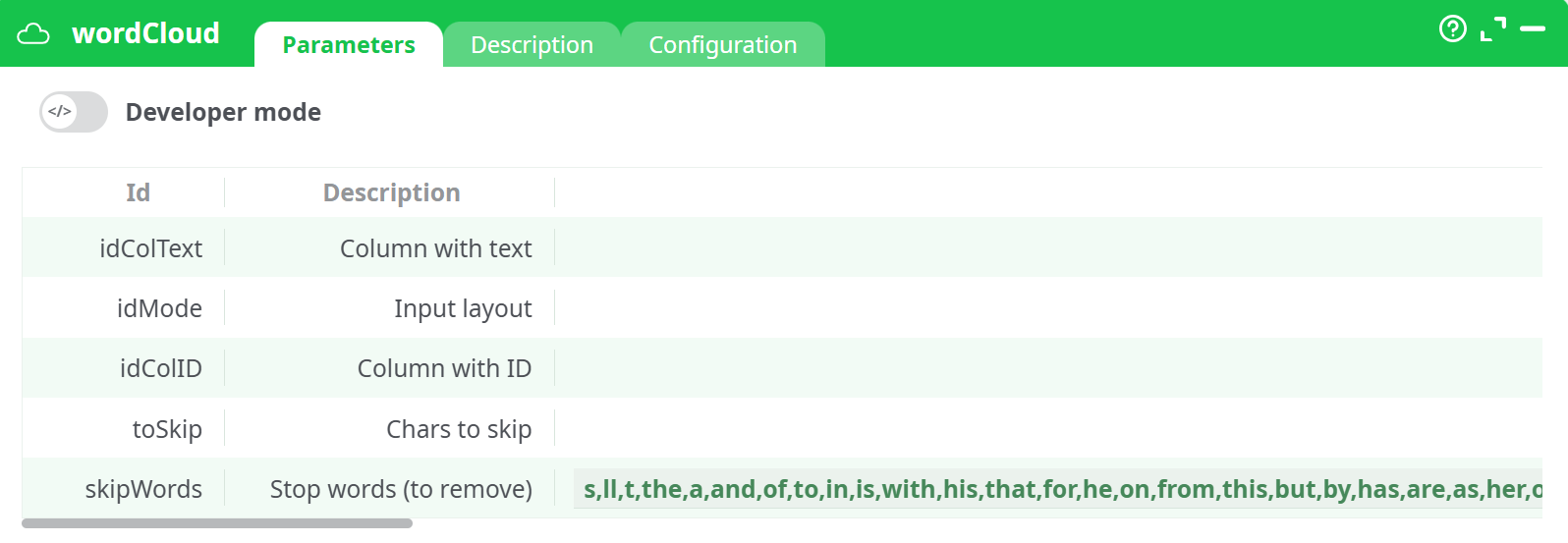
Parameters:
- Developer mode: activate/deactivate code tab.
- column with text
- column with ID
- chars to skip
- stop words (to remove)
¶ Description tab
See dedicated page for more information.
¶ Code tab
wordCloud is a scripted action. Embedded code is accessible and customizable through this tab.
¶ Configuration tab
See dedicated page for more information.
¶ About
The wordCloud action processes text data and generates a frequency table of words, excluding unwanted characters and stop words.
It is typically used to extract keyword insights or visualize term distribution from documents or textual datasets.
¶ Key Features
- Allows input in the form of individual text rows (e.g., one document per row).
- Supports removal of punctuation and custom stop words.
- Outputs a clean list of extracted words with their position and length per text.
¶ Example Input
| id | text |
|---|---|
| 1 | The quick brown fox jumps over the lazy dog. |
| 2 | Data science and machine learning are transforming industries. |
| 3 | Python is a powerful tool for data analysis and automation. |
¶ Example Configuration and Output
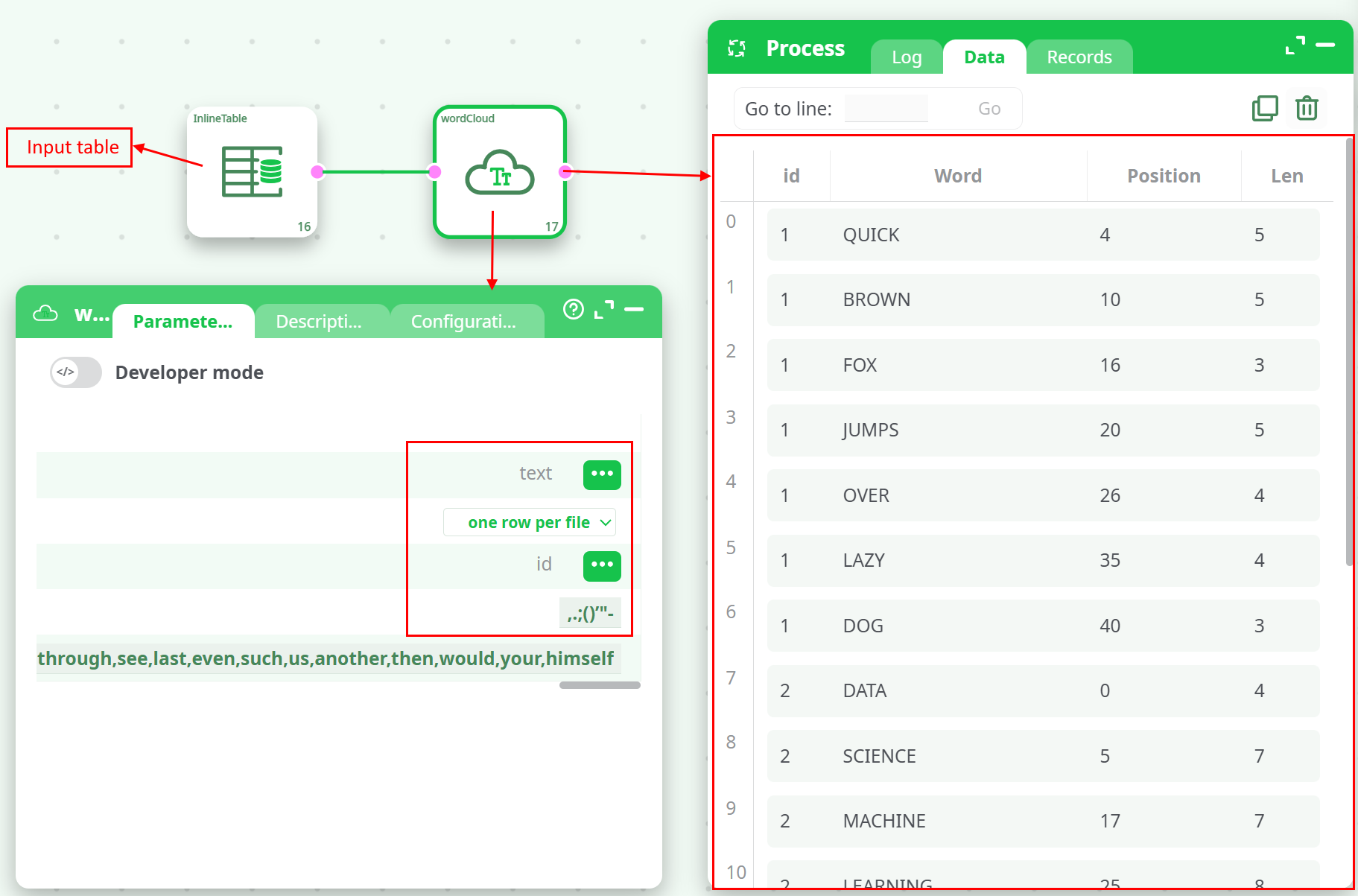
¶ Visual Preview
Each row's content is tokenized, cleaned, and processed into a structured list of relevant words. This can later be used to build word cloud visualizations or keyword analytics dashboards.
¶ Best Practices
- Use the skipWords field to exclude common filler words that don't add value.
- Set toSkip to include all characters you'd like removed from the text.
- Always provide an ID column when multiple rows are processed independently.
¶ Use Cases for wordCloud
The wordCloud action is designed for text analysis and keyword extraction. It is ideal for scenarios where you need to extract, clean, and analyze frequent terms from textual data.
-
Keyword Extraction from Customer Feedback
You can process a dataset of customer reviews or survey responses to identify commonly mentioned terms — revealing pain points, praise, or trending topics. -
Generating Visual Word Clouds
The output of this action can be fed into a visualization component (e.g., d3.js or Tableau) to create visual word clouds showing the most frequent words in large bodies of text. -
Preprocessing for NLP and Machine Learning
wordCloud can act as a text-cleaning step to:
- Remove stop words
- Normalize inputs
- Structure textual data into tokens
You can use it to prepare features for models like:
- Topic modeling
- Document classification
- Sentiment analysis
-
Summarizing Research Papers or Articles
Use this action to process collections of academic papers, news articles, or blog posts to extract dominant terminology and highlight frequently discussed concepts. -
Content Quality Checks
Detect overused filler words or unnecessary repetition in editorial workflows by extracting and quantifying word usage.
