¶ Description
Insert/Update/Delete some rows inside a relational database using the ODBC driver.
¶ Parameters
¶ Standard tab
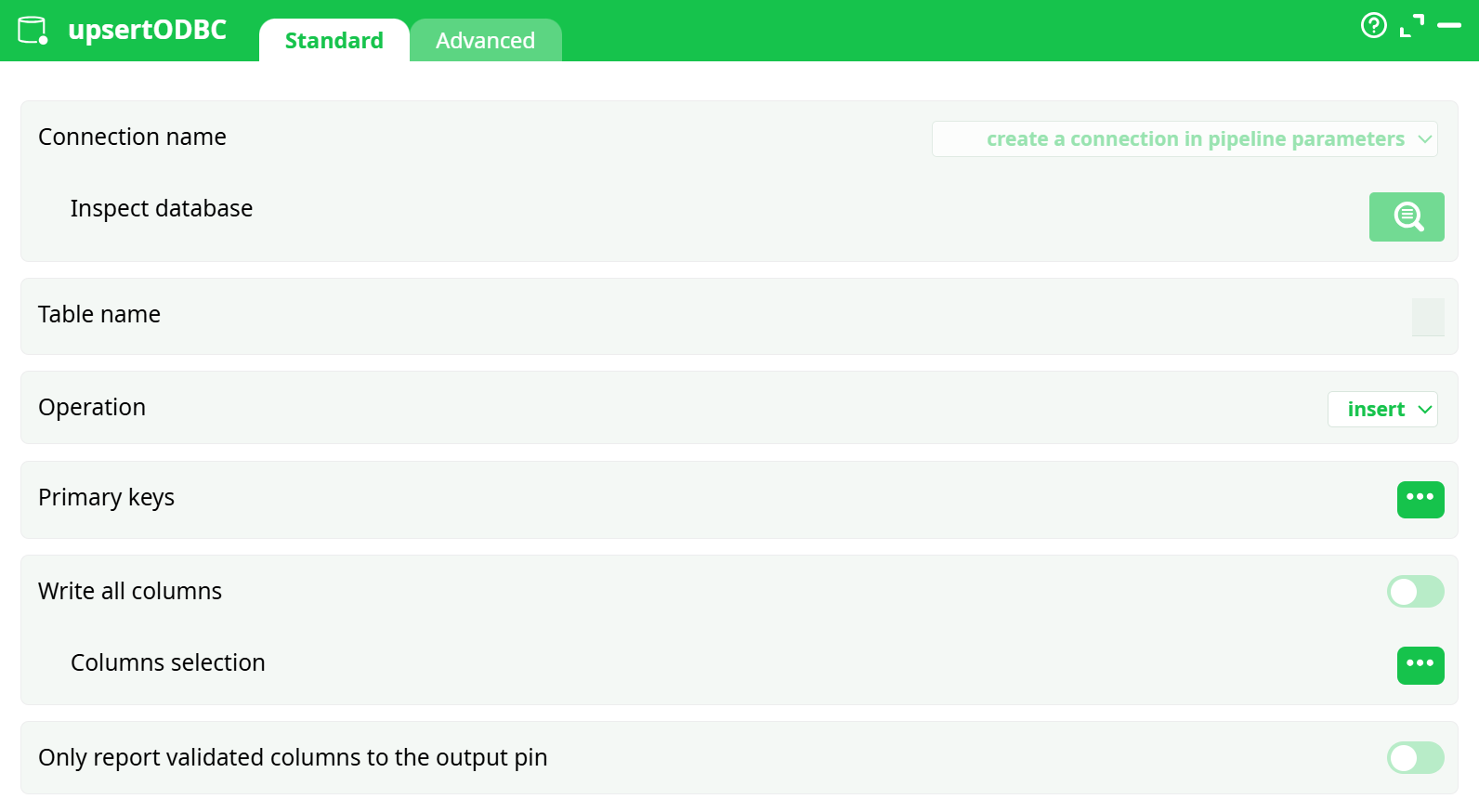
Parameters:
- Connection name
- Table name
- Operation on rows
- Primary keys
- Write all columns
- Only report validated columns to the output pin
¶ Advanced tab
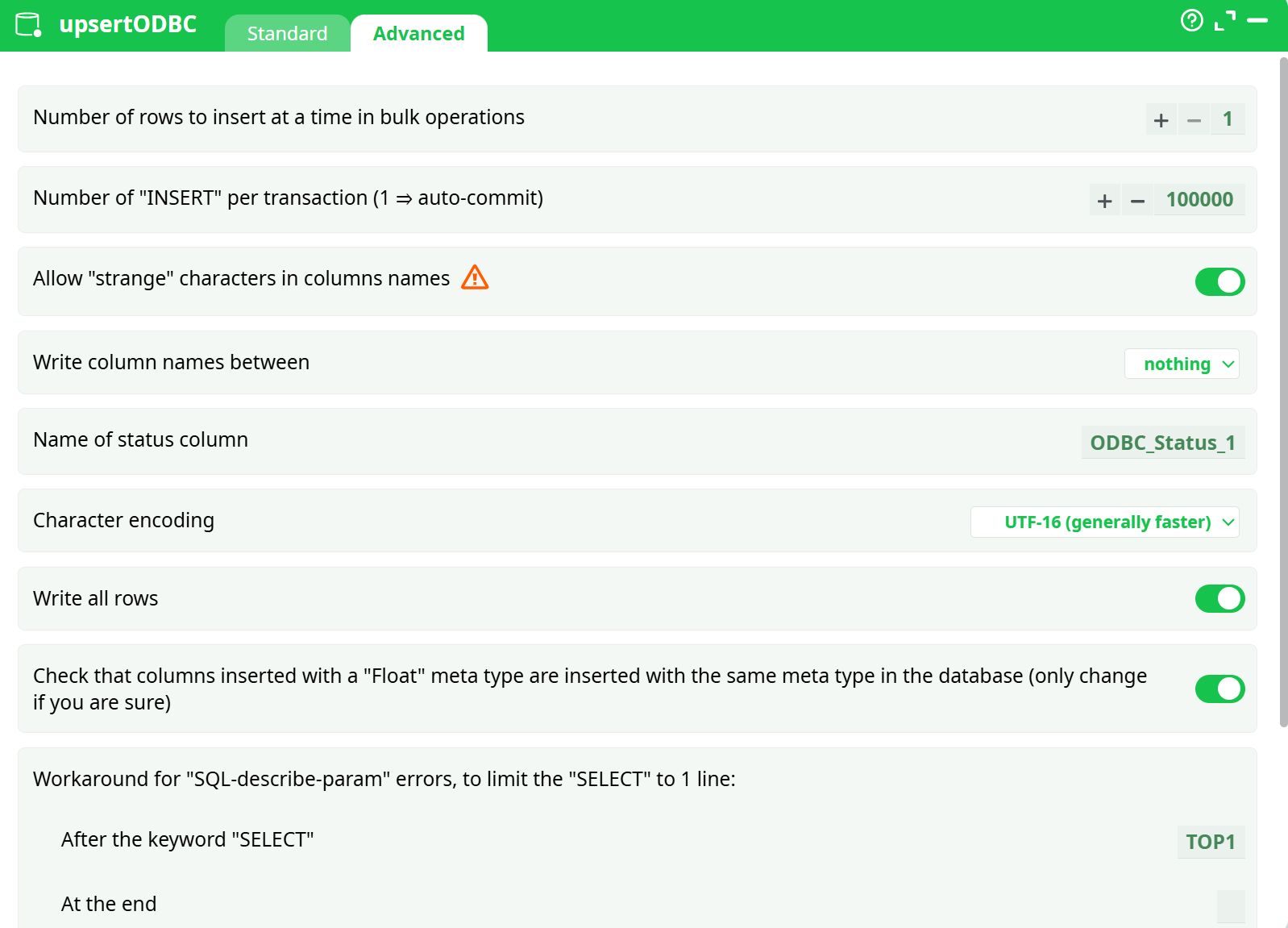
Parameters:
- Number of rows to insert at a time in bulk operations (BULK)
- Number of "INSERT" per transaction (1 = auto-commit)
- Allow "strange" characters
- Write column names between
- Name of status column
- Character encoding
- Write all rows
- Check that columns inserted with a "floating" meta type are inserted with the same meta type in the database (only change if you are sure)
- Workaround for "SQL-describe-param" errors, to limit the "Select" to 1 line:
- After the keyword "SELECT"
- At the end
¶ About
This action Insert, Update or Delete some rows inside a relational database using the ODBC driver.
This ETL-Pipeline first attempts to insert some new rows into a table inside a relational database. Some of these rows already exist inside our relational database. These rows will trigger an error at each attempt of insertion. These “insertion” errors are signaled inside the output column “ODBC_Status_1”: i.e. the column “ODBC_Status_1” contains “ERROR” for all failed insertion. Thereafter, there is a second “ODBC writer” that takes as input all the rows with an insertion error and performs an “update” on them.
The “Insert”, “Update” and “Delete” operations are sent “in batch” to the database driver. The size of these batches (the number of “Insert”, “Update” and “Delete” operations in a batch) is the parameter is named “BULK operations”. Large-batch-size usually means higher performances but, unfortunately, not all the databases are working properly with large-batch-size. The safest option when working with low-grade database drivers is to set the “BULK operations” parameter to 1.
On most databases, using the “auto-commit” option is the fastest option because it means that the database does not have to manage all the ACID properties related to the processing of TRANSACTIONS. This is not always true: When the “target” table (i.e. the table to modify) has an index structure, it might be faster to use TRANSACTIONS: See the next section about this subject.
NOTE :
Oddly enough, the most efficient way to INSERT rows inside a “DB2” database is to use large TRANSACTIONS.
Indeed, DB2 is forcing a SYNCHRONIZE operation (i.e. an operation where the content of the database in RAM is “flushed out” to the hard drive, to prevent any data loss in case of electrical power cut) at the end of each and every TRANSACTION. It means that, if you are using “auto-commit”, DB2 peforms a SYNCHRONIZE operation for every row that is INSERT’ed inside the database: This dramatically slows down everything.
Since all SYNCHRONIZE operations are extremely slow, it means that, to get the highest speed when using DB2, the best option is to reduce to the minimum the number of TRANSACTIONS.
¶ Inserting Rows inside a Table with an INDEX
All databases are using an INDEX structure that allows them to quickly find a particular cell in a large table containing billions of cells: I suggest you to read the section 10.10.1. about this subject if you didn’t do it yet.
One very annoying side-effect of using an INDEX structure is that the “insert” type of operations are very slow. Indeed, each time you insert a new row inside a table, you must update the INDEX structure to reflect the presence of this new row: This is very slow! There are several “tricks” that you can use to avoid losing time (because always updating this INDEX structure after each insertion of a new row consume a large amount of time): i.e. To add many rows inside an already existing Table T at high speed, you can use different solutions:
“Fast INSERT” Solution 1
The solution 1 is composed of 3 steps:
- Delete all INDEX structures built on top of table T (i.e. run many “DROP INDEX” SQL commands)
- Insert your new rows
- Re-create all the INDEX structures built on top of table T (i.e. run many “CREATE INDEX” SQL commands) Most of the time, this first solution is impractical and it’s almost never used.
Indeed, when using the solution 1, there are no “INDEX” on your table anymore during a brief amount of time (i.e. during the time required to insert all your rows): ..And this is very dangerous because all the processes that are attempting to run a query on the Table T will most certainly fail (because these processes will “time out” because they will run very slowly because there are no “INDEX” currently available). Furthermore, the time required to re-create all the INDEXes is usually so large that it completely nullifies the speed gain obtained by inserting the row at a slightly higher speed.
“Fast INSERT” Solution 2
The solution 2 is also composed of 3 steps:
- Insert all your new rows inside an intermediary table that has no INDEX
- Run a INSERT INTO SELECT * FROM SQL command. If the database engine is correctly coded, it should see that it only need to update one time the INDEX structure, once all the rows from the intermediary table have be added to the final Table T.
- Empty the intermediary table (i.e. run a “TRUNCATE TABLE” SQL command). When youd irectly insert news rows one-by-one inside the final Table T (in a simple, straightforward way), the database engine must update the INDEX structure thousands of times (i.e. there is one update for each inserted row). Using the “solution 2” allows to reduce the number of updates of the INDEX-structure to only one, leading to a large gain in time. Unfortunately, the solutions 2 also involves copying a large amount of data (from the intermediary table to the final Table T). This large “copy” operation might consume so much time that, at the end, the final gain in time might be null.
“Fast INSERT” Solution 3
When ETL communicates with a database, it sends to the database a large buffer that contains many INSERT expressions to be executed by the database engine. The quantity of INSERT operations that are sent inside the same buffer to the database engine is defined using the parameter named “BULK Operation” here:

Most (Java) ETL engines are not able to use any BULK Operations: i.e. They are sening to the database engine only one only “INSERT” SQL command at-a-time. Doing so, leads again to a very low insertion speed (because, for each inserted row, there is an update of the INDEX-structure). More precisely, if there are N rows to “insert”, the ETL engine will send N “text buffer” to the database engine, (each “text buffer” containing one “INSERT” SQL command) and the database engine might then run N “INDEX-structure-update”.
A clever database engine will see that this “buffer” contains many INSERT statements (several thousands) and only update the INDEX-structure once the complete set of INSERT statements has been completely processed. Thus, instead of running an “INDEX-structure-update” for each inserted row, we run an “INDEX-structure-update” every 10 thousand rows (i.e. at the end of each buffer). This leads to large time savings (but, unfortunately, not all databases are “clever”).
“Fast INSERT” Solution 4
ETL is also able to include inside the same transaction many different “INSERT” statements. For example, if you want to “group together” 3 “INSERT” statements together inside the same transaction, you can use the following parameters insde ETL :
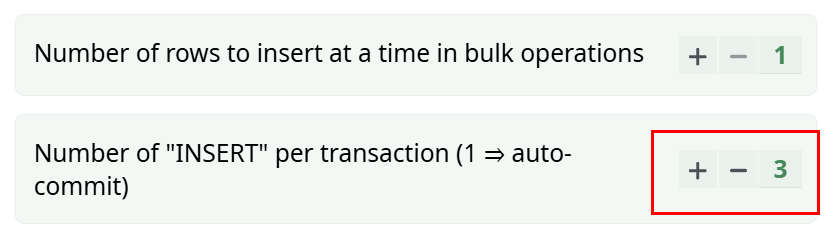
A clever database engine will see that each transaction contains many INSERT statements (sometime several thousands) and only update the INDEX-structure once the complete set of INSERT statements has been completely processed (i.e. when the transaction ends with the “COMMIT” statement). Thus, instead of running an “INDEX-structure-update” for each inserted row, we run an “INDEX-structure-update” every 10 thousand rows (i.e. at the end of each transaction). This usually leads to large time savings.
Unfortunately, running any kind of transactions inside a database always incurs a large overhead (because of the mechanims used to guarantee the ACID properties of the transactions, that are very time-consuming). This processing overhead dramatically slows down the “INSERT” speed. So, the time gained by reducing the number of “INDEX-structure-update” might anyway finally be lost again because of the overhead of the transaction mechanism.
NOTE
Which “Fast INSERT” solution (1-4) is best for which database?
Oracle: Solution 4 (or 3) is usually the best
MS-SQLServer: Solution 3 (or 4) is usually the best
Teradata: Solution 2 is usually the best (if you use it at the same time as the special TeradataWriter Action)
DB2: Solution 4 is usually the best (the DB2 database does not exactly support transactions but the “commit” keyword is useful to improve the “INSERT” speed for still other reasons)
