¶ Description
Anonymize/Encrypt columns using SHA256
¶ Parameters
¶ Standard tab

Parameters:
- Operating mode
- Columns to anonymize/hash
- Optional: key (or salt)
- Column name's suffix
¶ Description tab
See dedicated page for more information.
¶ Configuration tab
See dedicated page for more information.
¶ About
anonymizeSHA256 irreversibly anonymizes one or more columns by hashing their values with SHA-256. It’s useful when you need to share or analyze data without exposing direct identifiers (emails, phone numbers, IDs). The action can either overwrite the original columns or append hashed copies with a suffix.
⚠️ One-way by design. Hashed values cannot be recovered. If you need to later decrypt/recover values, use an encryption action instead (not hashing).
¶ What it outputs
-
A dataset identical to the input except for:
- update columns: selected columns are replaced by their SHA-256 hashes.
- add columns: new columns
<original><suffix>are appended with the hashed values.
-
No new files are written by this action; the result flows downstream in the pipeline.
-
The Data panel shows the transformed table so you can verify the change quickly.
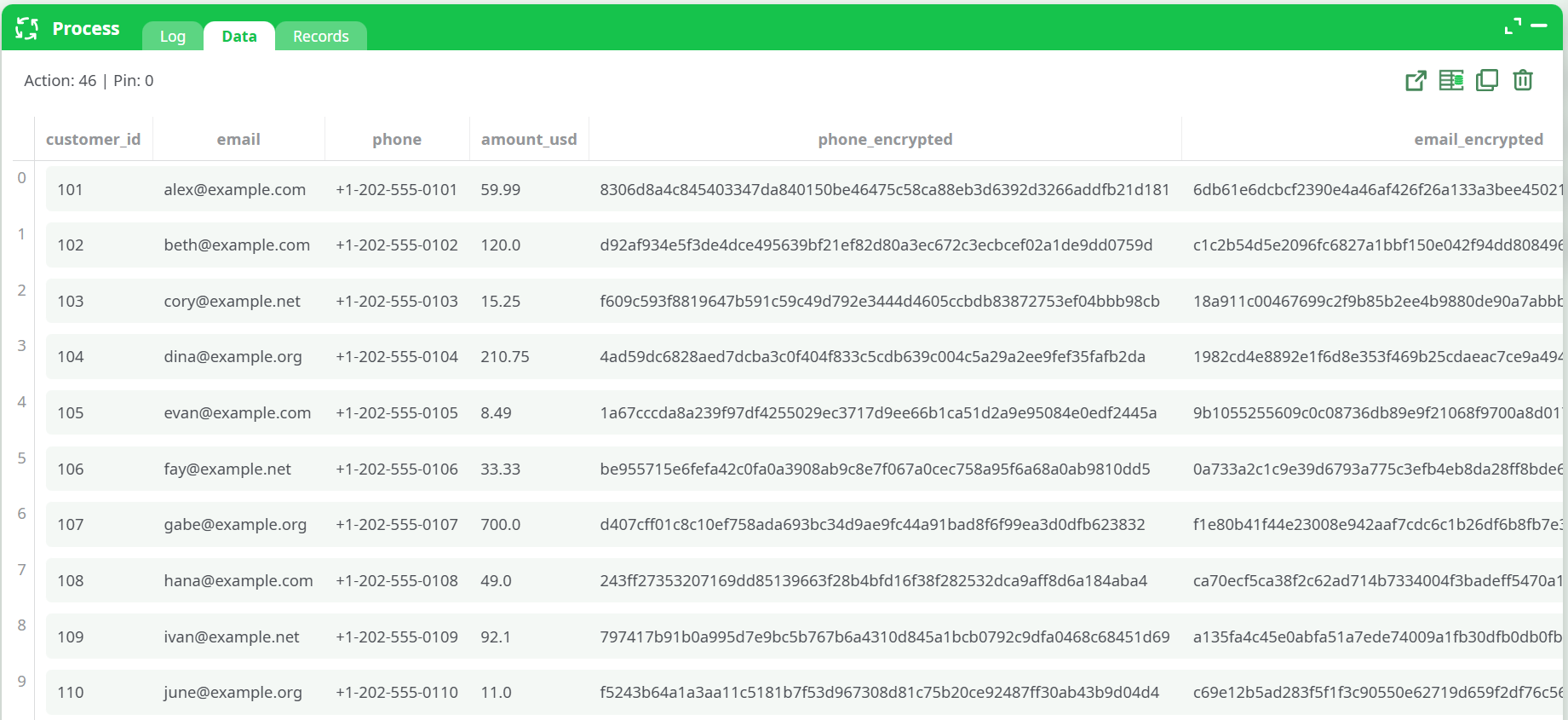
¶ Quick start
- Place
anonymizeSHA256after a step that produces a table (for example, a CSV reader). - Operating mode: choose add columns.
- Columns to anonymize/hash: select
email, phone(or any PII columns you have). - Optional salt: choose a pipeline secret (recommended) or leave empty for plain SHA-256.
- Suffix: keep
_encrypted(resulting columns:email_encrypted,phone_encrypted). - Run preview. In Data, you should see the two new hashed columns while the originals remain unchanged.
¶ Good practices
- Always use a secret salt in production to defend against rainbow-table and dictionary attacks.
- Decide joinability upfront.
If you need to join anonymized datasets across jobs, use the same salt consistently. If you must prevent cross-project joins, use different salts per project. - Prefer “add columns” while iterating. It preserves the original data for validation and makes it easy to compare.
- Document the suffix convention (
_encrypted,_hashed, etc.) so downstream users know which columns are masked. - Remember it’s irreversible. Don’t pick update columns unless you truly no longer need the originals.
¶ Troubleshooting
- “Column not found” – ensure the selected names exactly match the dataset schema (case and spacing included).
- Unexpected nulls – null/empty inputs remain null after hashing by design.
- Downstream type issues – hashed values are strings; if a consumer expects numeric types, adjust their logic.
¶ Security & compliance notes
- SHA-256 is deterministic: identical inputs (with the same salt) produce identical outputs, which enables grouping and joins without revealing the original values.
- Collision risk with SHA-256 is negligible for practical purposes, but if you need absolutely collision-free, reversible protection, use encryption rather than hashing.
- Treat the salt as sensitive. Store it in your platform’s secrets; rotate if compromised.
¶ Example scenarios
- Mask direct identifiers before exporting a dataset to a less trusted environment.
- Link records across systems without exposing PII: hash with a shared salt in both pipelines and join on the hashed key.
- A/B data sharing: provide partners only with hashed columns while retaining original ones internally.
