¶ Description
Joins two tables based on text approximation.
¶ Parameters
¶ Parameters tab
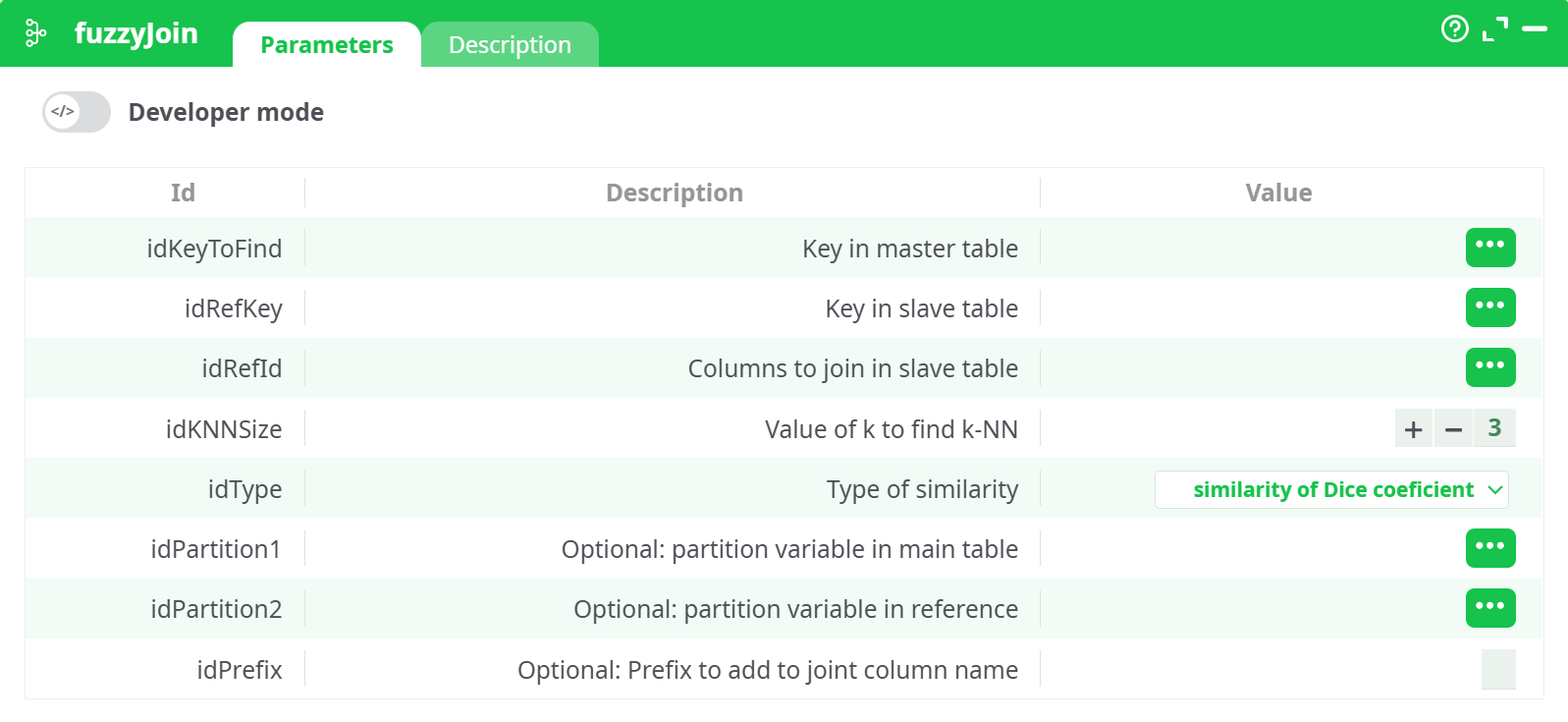
Parameters:
- Key in master table (idKeyToFind) — column from Pin 0 to match (e.g.,
Name). - Key in slave table (idRefKey) — key column in Pin 1 (e.g.,
Name). - Columns to join in slave table (idRefId) — one or more columns from Pin 1 to bring back (e.g.,
Region). - Value of k to find k-NN (idKNNSize) — how many candidates to return per row (1, 2, 3…).
- Type of similarity (idType) —
Jaro Winkler•Damerau LevenStein (distance)•similarity of Dice coefficient. - Optional: partition variable in main table (idPartition1) — compare only rows sharing the same value (e.g.,
Country). - Optional: partition variable in reference (idPartition2) — matching partition in Pin 1.
- Optional: prefix to add to joint column name (idPrefix) — text prepended to the returned reference columns (e.g.,
Region_).
¶ Description tab
Parameters:
- Script name
- Short description
- Revision
- Description
¶ About
fuzzyJoin matches records between two datasets when the keys are close but not exactly equal.
Instead of a strict = join, it computes a similarity (or distance) between the key in the main table and the key in the reference table, then returns the k nearest candidates together with their scores and any columns you choose to bring back from the reference.
It supports three proven string-comparison methods:
- Jaro–Winkler (similarity) — best for short strings, transpositions and common typos.
- Damerau–Levenshtein (distance) — number of edits (insert, delete, replace, transpose) needed to transform one string into another.
- Dice coefficient (similarity) — robust when matching multi-word names and phrases.
Why you need it. In real datasets, people type “Jonson” for “Johnson”, “Acme Inc.” for “ACME”, or swap first/last names. Regular joins drop those rows.
fuzzyJoinlets you recover them, score them, and decide how strict you want to be.
¶ A motivating example
Let’s imagine we have three tables in which a key has not been defined, and we want to use names to join them:
- Table 1 — Name ↔ Company
- Table 2 — Name ↔ Region
- Table 3 — Name ↔ Title
Humans sometimes input data incorrectly:
- “Daniel Soto Zeveart” in one table,
- “Daniel Soto Zevaart” in another,
- “Soto Zeevaert Daniel” in a third.

Jaro–Winkler and Damerau–Levenshtein will recover many of these, but depending on the particular typo or word order, some matches will still be missed. In practice, Dice coefficient tends to work well across all such cases because it compares common sets of word tokens rather than character-by-character order alone.
For upstream cleanup (lower/trim/remove accents), Correct Spelling
¶ How it works (at a glance)
- Read the main table on Pin 0 and the reference table on Pin 1.
- Select the key column in the main table (e.g.,
Name) and the key column in the reference table (alsoName). - Choose which reference columns you want to bring back (e.g.,
Region) and an optional prefix (e.g.,Region_). - Set the matching method and the number of neighbors k you want per row.
- Optionally restrict matching within logical groups using partitions (Country/Brand/Year).
- Run preview. The output shows
ClosestKey_1…kandSimilarity_1…k(orDistance_1…k) plus any reference columns for each candidate.
¶ Output schema
For each row in Pin 0, you get:
-
Original columns from the main table.
-
For each
n = 1…k:- ClosestKey_n — the matched key value from Pin 1.
- Similarity_n (for Jaro–Winkler/Dice) or Distance_n (for Damerau–Levenshtein).
- Each selected reference column with the chosen prefix and
_nsuffix, e.g.:
Region_Region_1,Region_Region_2, … (ifidPrefix = Region_and you selectedRegion).
¶ Recommended settings
- General purpose names/companies:
similarity of Dice coefficient,k = 3. - Short strings with swaps/typos:
Jaro Winkler,k = 3. - You want an “edits to fix” interpretation:
distance of Damerau LevenStein,k = 1–3. - Large datasets: use partitions (
Country,Source,Brand) to compare only within the same bucket. - Production: keep
k = 1and follow with a Filter (Similarity_1 ≥ 0.85orDistance_1 ≤ 1) to accept only strong matches.
¶ Step-by-step tutorial
-
Pipeline layout
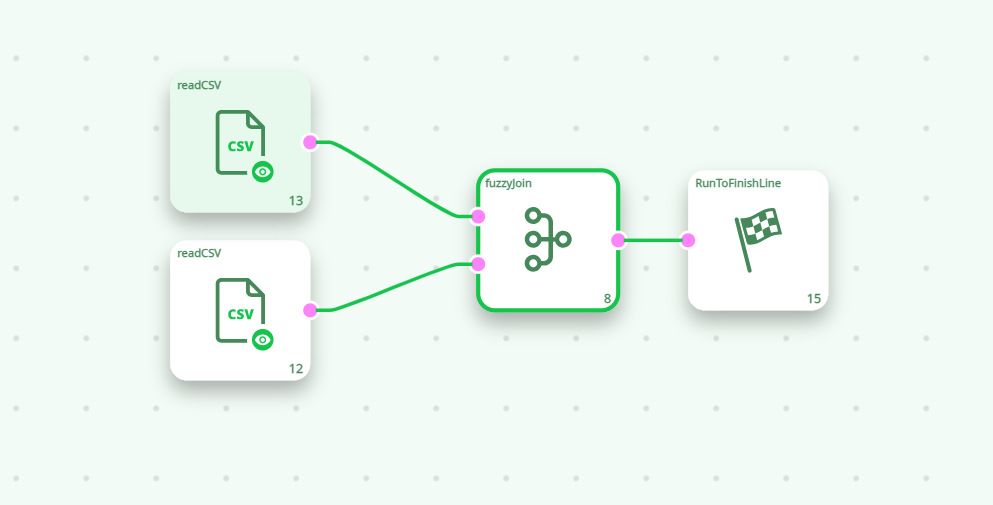
-
Read the main table (Pin 0)
- Action:
readCSV→ file with columnsName, Company.
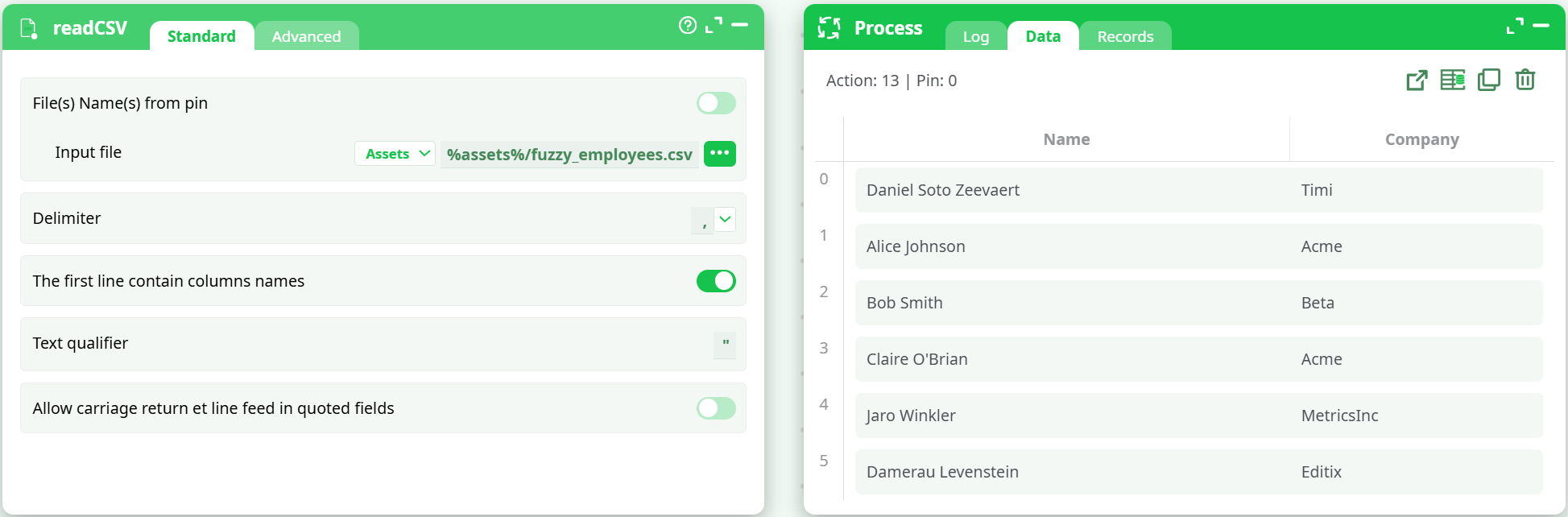
- Action:
-
Read the reference table (Pin 1)
- Action:
readCSV→ file with columnsName, Region.
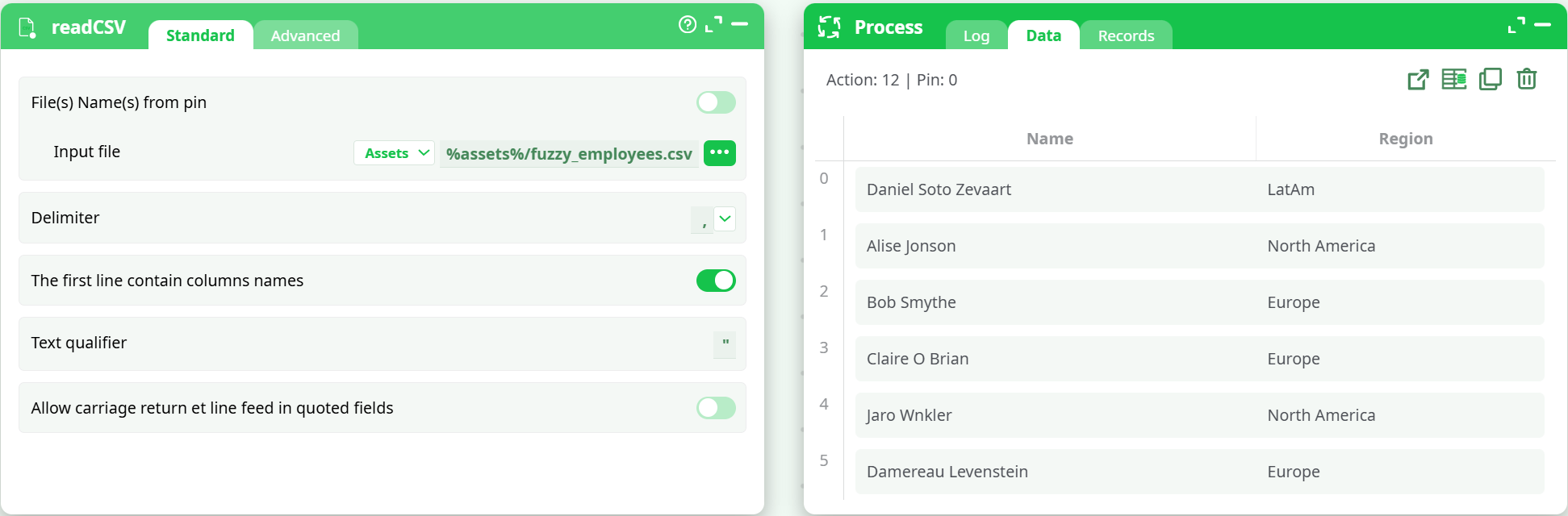
- Action:
-
Select columns in fuzzyJoin
- Key in master table:
Name - Key in slave table:
Name - Columns to join in slave table:
Region - k:
1 - Type of similarity:
similarity of Dice coefficient - Prefix:
Region_
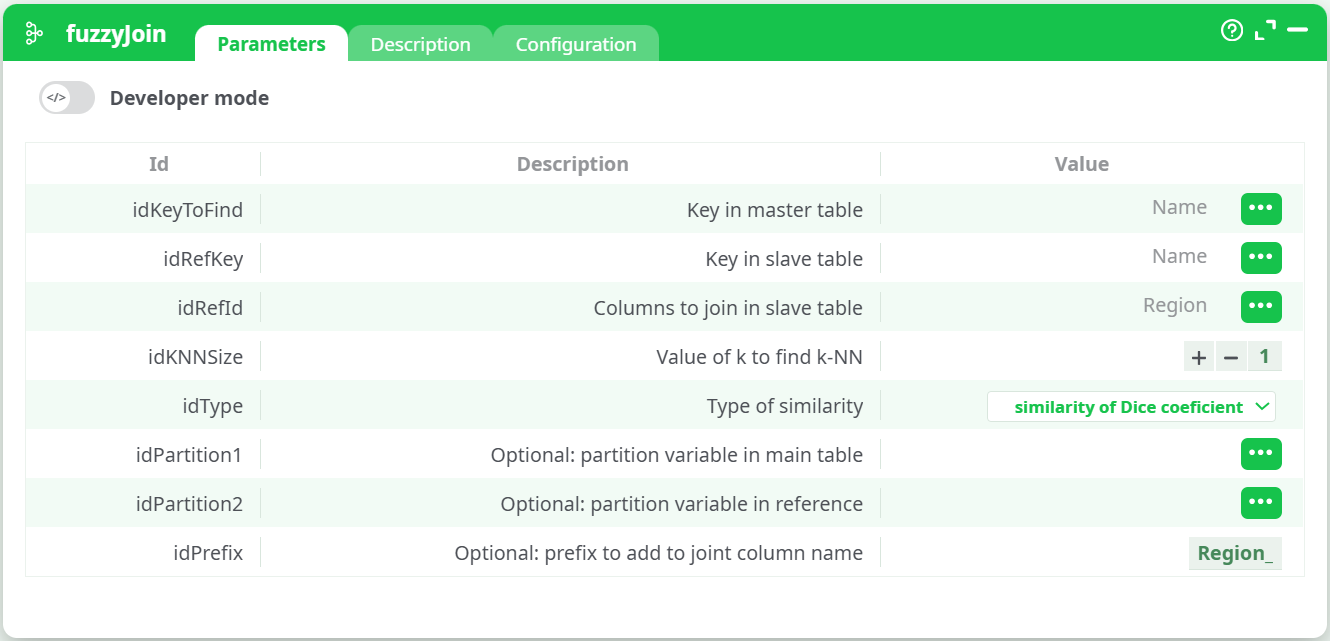
- Key in master table:
-
Preview results (Dice)
- Inspect
ClosestKey_1,Similarity_1, andRegion_Region_1.
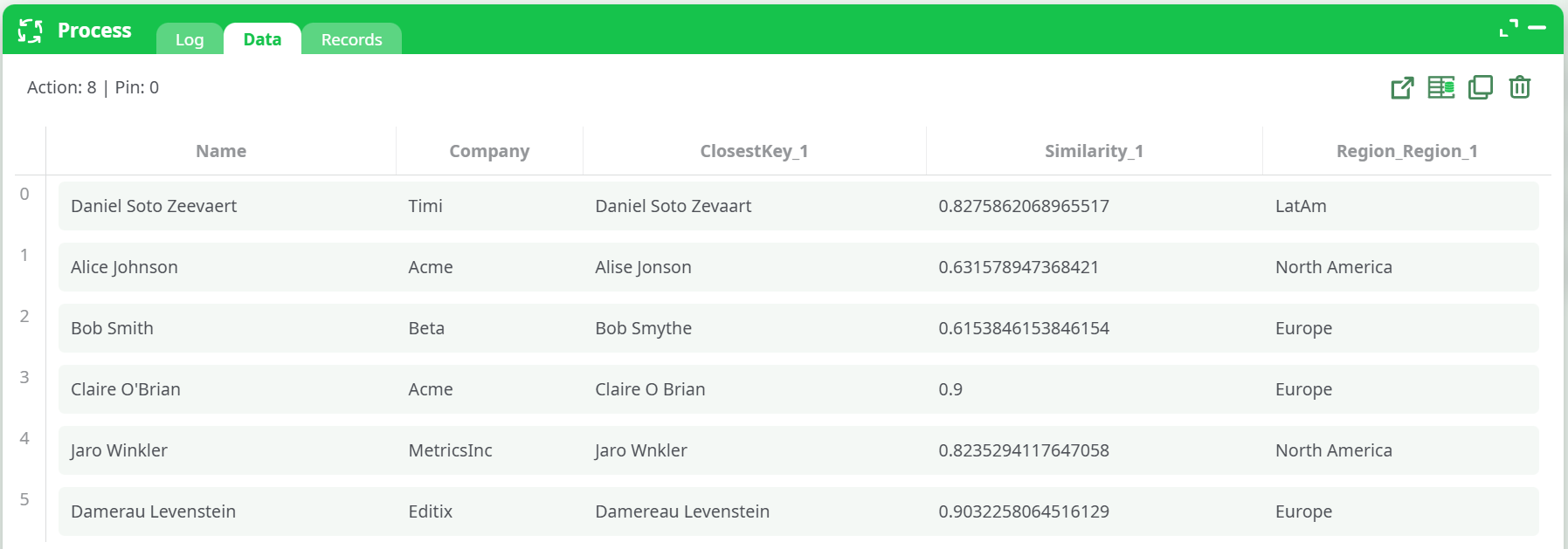
- Inspect
-
Compare metrics
- Change to Jaro Winkler and preview.
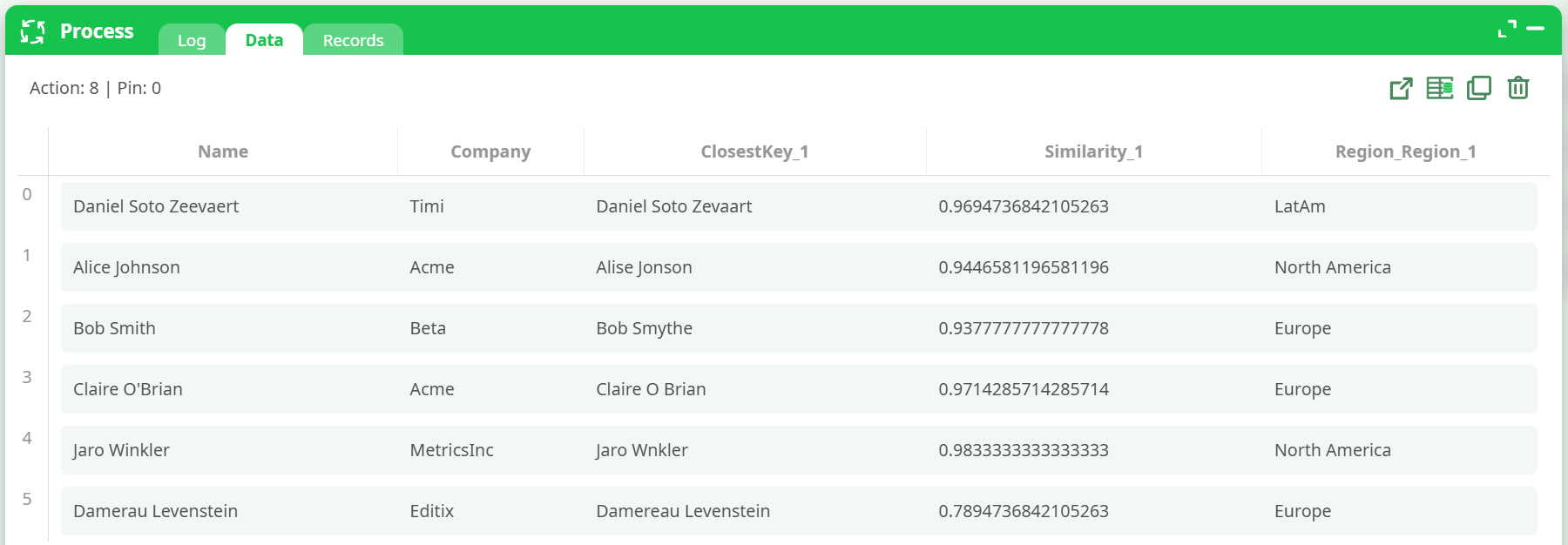
- Change to distance of Damerau LevenStein and preview.
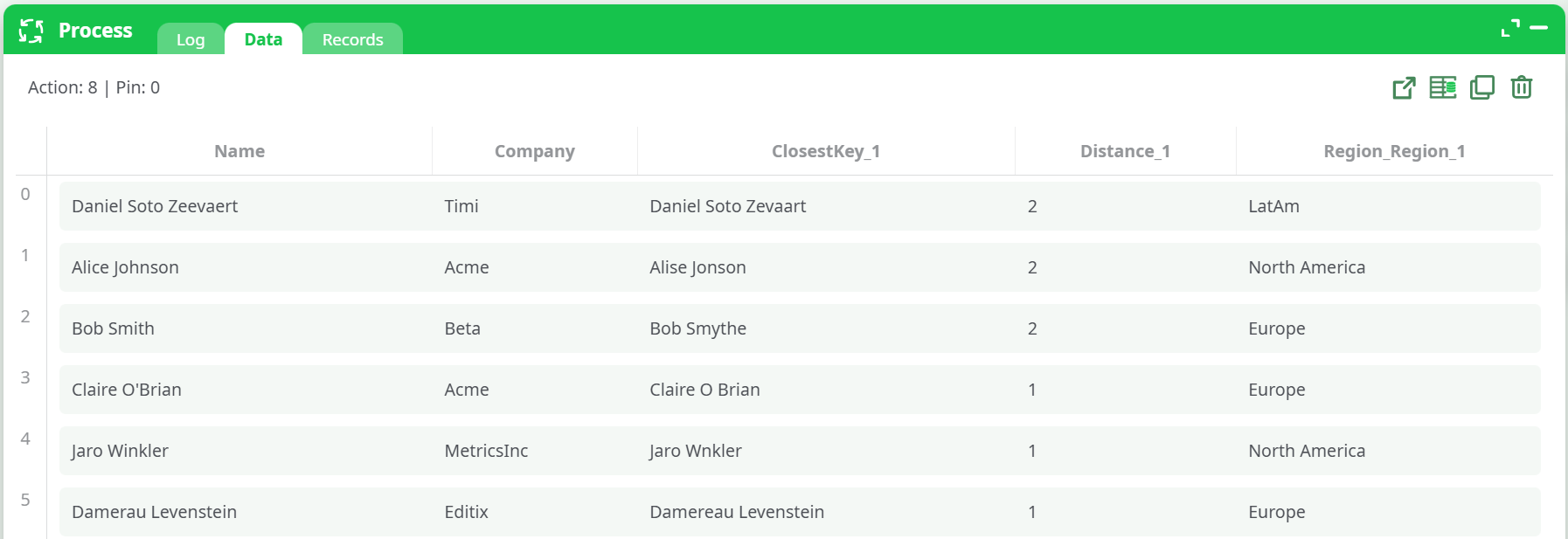
- Change to Jaro Winkler and preview.
¶ Tips & best practices
- Normalize first. Lowercase, trim spaces, remove accents/punctuation. Your scores will jump.
- Tokenization helps. Dice coefficient compares token sets; pre-splitting “last, first” formats can help other metrics too.
- Tune
k. Start withk = 3to inspect alternates; move tok = 1in production. - Explainability. Keep the scores/alternates for audit or human review queues.
- Performance. Use partitions and reduce
kfor very large tables.
¶ Troubleshooting
-
“The column ‘X’ is missing on input pin 1 / initialization of ‘idRefId’ failed.”
The chosen column to join from the reference does not exist (often a mis-selected pin). Open the selector and pick a column from Pin 1. -
Low similarities across the board.
Normalize text, try Dice, and lower the threshold temporarily to inspect what the model is comparing. -
Too many look-alike matches.
Reducek, raise your acceptance threshold, and/or add partitions to limit comparisons to the right cohort.
